Responsive Websites können nicht nur auf die Änderung des Browserfensters reagieren – auch die Umgebungshelligkeit kann die Gestaltung beeinflussen. Mit Javascript lassen sich entsprechende Sensoren abfragen und für das Design nutzen.
Traditionell denkt man bei responsivem Webdesign an Layouts, die auf die Änderung der Browserfenstergröße – bzw. des Viewports – reagieren (wenn man bei einer so jungen Disziplin von Traditionen sprechen kann). In der Regel werden dann das Layout der Seite oder einzelne CSS-Eigenschaften verändert, z.B. die Schriftgröße, um die Benutzung für Besucher unter den für sie geltenden Bedingungen (besonders kleine oder große Bildschirme) zu verbessern. Tatsächlich gibt es aber ein ganze Reihe von Umgebungsbedingungen, auf die eine Website reagieren könnte.
Schön wäre es doch, wenn ein elegant Ton in Ton gestaltetes Design auch bei grellem Sonnenlicht gut lesbar wäre – indem sich der Kontrast den Lichtverhältnissen anpasst. Tatsächlich ist das möglich. Mit der W3C Candidate Recommendation Ambient Light Events hat die Mozilla Foundation eine Spezifikation eingereicht, mit der sich das über einen Lichtsensor gemessene Umgebungslicht auslesen und verwerten lässt (wenn auch momentan die Browserunterstützung noch sehr ausbaufähig ist). Auch der aktuelle Draft der Mediaqueries Level 4 sieht eine Reaktion auf Helligkeitsunterschiede vor – das Media Feature luminosity. Während die Mediaqueries noch nicht einmal testbar sind, lässt der Mozilla-Vorschlag mit Mobile Firefox > 15 oder auf FirefoxOS bereits nutzen (z.B. einem Nexus 7 der 1. Generation).
Die Abfrage an sich ist recht einfach. Mit einem Event Listener wird der Sensor direkt abgefragt:
Mit dem gewonnenen Helligkeitswert in Lux könnt ihr nun Abfragen für die Anpassung des Design an die Umgebungshelligkeit schreiben. Der Wert lässt sich natürlich auch direkt anzeigen. Die folgende Funktion setzt je nach Helligkeit unterschiedliche Klassen und gibt den Lichtwert aus:
Das Skript wird im Kopf der Website platziert und stellt die vergebenen Klassen zum Styling zur Verfügung. Außerdem verändert es den Inhalt des Elements mit der id "message". Mit einer CSS-Transition könnt ihr den Übergang noch etwas verfeinern und für den Alltagseinsatz wäre es sinnvoll, die Schwellenwerte so zu gestalten, dass die Darstellung nicht andauernd umspringt (Hysterese).
Um den Effekt zu sehen, müsst ihr die Demoseite mit Mobile Firefox auf einem Gerät mit Helligkeitssensor aufrufen.
Es gibt noch mehr!
Auf die Umgebungshelligkeit zu reagieren, ist nur eine Möglichkeit, die wachsende Anzahl von Sensoren moderner Mobilgeräte zu nutzen.
Wie wäre es zum Beispiel, wenn die Website eines Restaurants beim Aufruf durch ein mobiles Gerät »in der Nähe« mit der prominenten Anzeige der Tageskarte und der Adresse reagieren würde? Die meisten modernen Smartphones haben außerdem einen Kompass und einen Neigungssensor an Bord, so dass sich die Position des Geräts im Raum exakt bestimmen lässt. Eine Kleinigkeit, nun auch noch die Entfernung und Richtung zum Ziel anzuzeigen.
Bei der Nutzung von Sensoren stellt sich natürlich die Frage nach Datenschutz und Überwachung. Da die Sensorendaten vom Gerät bereit gestellt werden und per Javascript verarbeitet werden, bleiben alle Informationen zunächst auch dort (natürlich lassen sie sich dann auch weitergeben). Manch Nutzer wird sich aber dennoch durch Funktionen irritiert fühlen, die zeigen, dass »die Website« seine Position kennt. Mit einem Datenschutzhinweis, der die Funktion erläutert, nehmt ihr diese Bedenken ernst. Im Zweifel könnt ihr Lokalisierungsfunktionen auch so umsetzen, dass sie erst eingeschaltet werden müssen.
Progressive Enhancement statt Bevormundung
So nicht – eine mobile Website ist mehr als ein Adressaufkleber!
Bei aller Freude über zusätzliche Information solltet ihr jedoch nicht vergessen, dass Sensordaten immer nur Informationen aus zweiter Hand sind – einen Sensor für die Gedanken des Nutzers gibt es glücklicherweise (noch) nicht. Bietet daher aufgrund von sensorgestützten Vermutungen zusätzliche Verbesserungen an – trefft keine ausschließenden Entscheidungen für die Nutzer. Ein abschreckendes Beispiel sind »mobile Websites«, die nur die Anschrift eines Unternehmens anbieten, in der irrigen Annahme, dass mobile Nutzer ihr Smartphone oder Tablet immer nur unterwegs nutzen.
Alle Webworker, die CSS-Präprozessoren wie SASS nutzen, müssen sich die Frage beantworten: »Wie organisiere ich meine Dateien, um mir das (Arbeits-)Leben so einfach wie möglich zu machen?« Wer als Antwort auf diese Frage irgendwo das Ei des Kolumbus vermutet, wird erstaunt sein über die Vielfalt der Ansätze.
Viele Webworker haben sich hierzu kluge Gedanken gemacht und sind naturgemäß zu unterschiedlichen Ergebnissen gekommen (siehe auch die weiterführenden Links). Was allein deshalb nicht verwundert, da Strukturansätze immer auch unmittelbar die Gestaltungsprinzipien reflektieren, unter deren Prämisse ein Autor seine Styles schreibt. Und die sind oftmals sehr verschieden.
Es führen also mal wieder viele Wege nach Rom. Im Artikel stelle ich meinen Weg vor, Ordner und Dateien in einem SASS-Projekt zu organisieren und freue mich, wenn er Anregung ist, eigene Ideen zu entwicklen.
Viele Fliegen, eine Klappe
Ich vermeide es seit geraumer Zeit, eine individuelle Ordner- und Dateistruktur für neue Projekte anzulegen. Bis zu dieser Entscheidung musste ich meine Entwicklungsumgebung permanent anpassen; die gedankliche Umstellung kostete Zeit und war anstrengend. Im Laufe der kreativen Arbeit an einem Projekt permanent Entscheidungen über Organisation, Dateibenennung etc. treffen zu müssen, hemmt zudem den Arbeitsfluss und ist ineffizient.
Daher habe ich mir eine Mastervorlage erstellt, die seitdem Grundlage für jedes neue Projekt ist. Diese Mastervorlage besteht vorrangig aus einer bestimmten Ordner- und Dateistruktur, die sich bislang in sehr unterschiedlichen Projekten bewährt hat und mir erlaubt, mich ganz auf die Entwicklung des CSS eines Projektes zu konzentrieren. Ich habe mit ihr sowohl sehr einfach gehaltene Webseiten, als auch komplexere Projekte mit mehreren Teilbereichen umgesetzt.
Die Ordner- und Dateistruktur der Mastervorlage
utilities/
abstracts/
base/
extensions/
sections/
website/
queries/
vendor/
overrides/
_bootstrap.scss
_website-configuration.scss
website.scss
Für den Artikel ist die Mastervorlage schon um einen beispielhaften Projektbereich (website) erweitert. Was genau ein Projektbereich ist und was er enthält, beschreibt der Artikel im weiteren Verlauf.
utilities/
Hier liegen globale Mixins und Funktionen, die übergreifend in allen Projektbereichen einsetzbar sind. Als Teil der Mastervorlage stehen sie in jedem neuen Projekt unmittelbar zur Verfügung.
utilities/
_functions.scss
_mixins.scss
...
abstracts/
In diesem Ordner befinden sich ausschließlichAbstraktionen. Eine Abstraktion ist eine Art CSS-Blaupause, die die grundsätzliche Darstellung eines HTML-Elementes festlegt, aber keine Vorgaben zu dessen Aussehen macht. Dieses wird im CSS des jeweiligen Projektbereiches festgelegt. Harry Roberts hat das Prinzip anhand der Nav Abstraktion sehr anschaulich erklärt.
Um von Anfang an für die Einbindung von externen CSS-Frameworks gerüstet zu sein, ist der Hauptordner abstracts/ in zwei Unterordner (base/, extensions/) unterteilt. Während die eigenen Abstraktionen ihr Zuhause im Ordner base/ haben, liegen die erweiterten Abstraktionen eines externen Frameworks im Ordner extensions/. Durch diese Unterteilung des Hauptordners ist die Herkunft einer Datei auf einem Blick ersichtlich. Ein nicht zu unterschätzender Vorteil, wird ein Projekt zu einem späteren Zeitpunkt erneut bearbeitet.
Sehr hilfreich ist, den Namen der im Ordner extensions/ liegenden Dateien mit einem Prefix zu versehen (hier: ext-). Werden in der Entwicklung Sourcemaps genutzt, ist es so ein leichtes, zwischen Original und angelegter Datei im Browser zu unterscheiden.
abstracts/
base/
_name-der-abstraktion.scss
...
extensions/
_[ext]-name-der-abstraktion.scss
...
Webworker sollten soviel Zeit wie möglich auf die Erstellung eigener Abstraktionen verwenden! Da der Ordner abstracts/ Bestandteil der Mastervorlage ist, profitiert ihr davon in jedem neuen Projekt.
Tipp: Wurde während eines Projekts eine neue Abstraktion erstellt, solltet ihr immer überlegen, ob es ggf. sinnvoll ist, sie in die Mastervorlage zu übernehmen.
Abstraktionen vorbereiten
In jeder dieser Dateien, werden die eigentlichen Deklarationen mit einer @if Kontrollanweisung umschlossen, die so aussehen sollte:
@if$use-abstract-[name-der-abstraktion] == true{
... Deklarationen ...
}// eol condition
bzw. für erweiterte Abstraktionen externer Frameworks:
Wozu diese Kontrollanweisungen genutzt werden, wird zu einem späteren Zeitpunkt im Abschnitt zur Konfigurationsdatei erklärt.
sections/
Der Ordner sections ist das Herz eines Projektes. In ihm liegt mindestens ein Bereichsordner (im Artikel: website) oder beliebig viele. Jeder Bereichsordner enthält sämtliche (S)CSS-Partials, die für die Struktur, das visuelle Erscheinungsbild und das Verhalten auf unterschiedlichen Geräten des jeweiligen Bereiches zuständig sind.
Zu jedem Projektbereich gehört sowohl eine korrespondierende Konfiguration (im Artikel: _website-configuration.scss) als auch die zu kompilierende Projektdatei (im Artikel: website.scss). Dies ermöglicht, Stylesheets für jeden einzelnen Projektbereich separat zu erstellen.
Dass das sehr sinnvoll sein kann, macht folgendes Beispiel deutlich: Der Kunde möchte für das Weihnachtsgeschäft einige Kampagnenseiten lancieren, die sich in Struktur und visueller Gestaltung signifikant von der generellen Webseite unterscheiden und unter jeweils eigenständigen Domains laufen sollen. Dies könnte mit dem schon vorhandenen Projektbereich website realisiert werden. Das aber hätte gleich mehrere Nachteile: Die Konfigurationsdatei würde unübersichtlich, dadurch schwer zu verwalten und das generierte CSS würde weder für die Webseite noch die Kampagnenseiten optimal. Beide Seitenbereiche würden Styles laden, die nicht genutzt werden.
Der deutlich bessere Weg ist das Anlegen eines zusätzlichen, neuen Bereich, der hier naheliegend campaigns genannt wird. Die Projektstruktur würde anschließend so aussehen:
...
sections/
website/
queries/
campaigns/
queries/
...
_campaigns-configuration.scss
campaigns.scss
_website-configuration.scss
website.scss
Media Queries
Jeder Bereichsordner beinhaltet einen Unterordner mit Namen queries/. Wie unschwer zu erraten, werden hier die media queries für den jeweiligen Bereich deklariert. Werden Media Queries in einer separaten Datei auf Ebene des Projektbereichs definiert, kann für jeden Teil des Projekts entschieden werden, wie er sich auf unterschiedlichen Geräten verhält und aussieht. So lange es in SASS nicht möglich ist Media Queries zu gruppieren, bevorzuge ich das Arbeiten in eigenständigen Dateien.
sections/
[name-des-projektbereichs]/
...
queries/
...
vendor/
Im globalen Ordner vendor/ liegen CSS-Dateien externer Bibliotheken. Damit der CSS-Präprozessor diese Dateien einbinden kann, wird das Suffix jeweils von .css auf .scss geändert. In der _overrides.scss Datei werden die Styles der externen Bibliotheken bei Bedarf überschrieben. So gehen die Änderungen nicht verloren, wenn die originalen CSS-Dateien dieser Bibliotheken aktualisiert werden.
vendor/
// Bsp. prism.css => prism.scss
prism.scss
...
overrides/
_overrides.scss
_website-configuration.scss
Die _[name-des-bereiches]-configuration.scss ist die Schaltzentrale eines jeden Projektbereiches (im Artikel: website). Ausschließlich hier werden die im jeweiligen Projektbereich genutzten Variablen deklariert. Die Datei teilt sich in mindestens drei Bereiche auf (zu viele kann es prinzipbedingt nicht geben. Seid kreativ!). Ein paar Tipps:
Farben
Die Definition von Farben sollte in zwei Bereiche unterteilt werden. Der Erste enthält Variablen, deren Benennung sich nach ihrem Wert richten (Bsp. $nearlyWhite: #f1f1f1;). Im zweiten deklariert ihr die Variablen, deren Name das widerspiegelt, wofür sie eingesetzt werden (Bsp. $pageBackgroundColor: $nearlyWhite!default;). Diese – und nur diese– werden im CSS genutzt. Was zuerst etwas umständlich wirkt, ist tatsächlich der Schlüssel zur Vermeidung von semantischen Sackgassen.
Interface
Das visuelle Erscheinungsbild seitenübergreifender Elemente (bspw. Schatten, Rahmen etc.) ist in der Regel überall identisch. Sie sind somit perfekte Kandidaten um als Konfigurations-Variablen deklariert zu werden. Teures Nachjustieren kann vermieden werden, indem zu Beginn des Projektes überlegt wird, für welche Elemente/Attribute eine Abstrahierung als Variable sinnvoll ist.
Includes
Wart ihr fleißig, liegen im Ordner abstracts/ (bzw. dessen Unterordnern) viele Dateien mit Abstraktionen. Um zu vermeiden, die globale _bootstrap.scss Datei (siehe nachfolgender Abschnitt) immer wieder erneut anpassen zu müssen, sobald eine neue Abstraktion erstellt worden ist, werden diese Dateien dort per Globbing (Sass Plugin) importiert. Was dazu führt, dass grundsätzlich alle– auch die im CSS nicht genutzten Abstraktionen – im generierten CSS auftauchen und die Dateigröße des kompilierten Stylesheets dadurch unnötig aufblähen.
Wie im Abschnitt zu den Abstraktionen erwähnt enthält jede dieser Dateien eine @if Kontrollanweisung: Zeit, sie zu nutzen! Es werden nur die Variablen explixit auf true gesetzt, deren Abstraktionen auch tatsächlich im CSS genutzt werden.
Tipp: Unabhängig davon, ob sie eingesetzt werden oder nicht: Es müssen grundsätzlich alle im Ordner abstracts/ vorhandenen Abstraktionen in der Konfigurationsdatei definiert werden, da der Compiler sich sonst über nicht definierte Variablen mokiert.
/**
* $CONFIGURATION
* Section: website
*/
/**
* $ACOLORS
* Variablen bezogen auf ihren Farbwert
*/
$nearlyWhite: #f1f1f1;
...
/**
* $COLORS
* Variablen bezogen auf ihren Verwendungszweck
*/
$pageBackgroundColor: $nearlyWhite !default;
...
/**
* $INTERFACE
* Rahmen, Schatten, Rundungen, Schriftgrößen, Basismaße etc.
*/
$borderRadius: 5px !default;
...
/**
* $INCLUDES
* Listing aller verfügbaren Abstraktionen
* Inkludiere (value => `true`) nur die Abstraktionen,
Die globale _bootstrap.scss Datei (die nichts mit dem gleichnamigen CSS-Framework zu tun hat) importiert alle Dateien, die keinen unmittelbaren Bezug zu einem dezidierten Projektbereich haben. Sie ist Teil der Mastervorlage. Auch werden hier die Styles der externen Bibliotheken inklusive der _overrides.scss Datei eingebunden.
Wichtige Regel: In der Bootstrap-Datei werden keine CSS-Styles deklariert! Nur so bleibt der globale Charakter der Bootstrap-Datei erhalten.
/**
* $BOOTSTRAP
* Section: global
*/
// Helfer wie functions, mixins importieren
@import "utilities";
// Es werden nur die Abstraktionen importiert deren Wert in
// der `_website-configuration.scss` auf `true` gesetzt ist
@import "abstracts/base/*";
// Abgeleitete Abstraktionen aus Drittanbieter-Frameworks
// einzeln importieren. "ext-" als Datei-Prefix verwenden
Hier nun kommt Dampf in den Kessel. Die website.scss ist die einzige Datei, die kompiliert und später im HTML verlinkt wird. Auch hier gilt: Vermeidet an dieser Stelle das Definieren von Styles! Diese gehören ausschließlich in die Dateien des jeweiligen Bereichsordners.
Die Reihenfolge der Importe ist relevant. In einem ersten Schritt wird die Konfiguration des Projektbereichs geladen, anschließend die _bootstrap.scss, die die globalen Funktionen und Abstraktionen sowie die Vendor-Styles einbindet und bereitstellt. Die bereichsbezogenen Partials werden zum Schluss importiert.
/**
* $COMPILE
* Section: website
*/
// Projektkonfiguration
@import "website-configuration";
// Globaler bootstrap
@import "bootstrap";
// Section styles importieren
@import "sections/website/*";
// Media queries importieren
@import "sections/website/queries/*";
Wie war das nochmal mit dem Ei?
Zu guter Letzt möchte ich dazu ermutigen, unterschiedliche Ansätze zur Strukturierung – damit ist auch der hier vorgestellte gemeint – immer wieder mit Blick auf die eigene Arbeitsweise und dem eigenem Arbeitsumfeld kritisch zu hinterfragen. Es gibt keinen allgemeingültigen richtigen Ansatz. Die Entscheidung für eine bestimmte Art der Organisation ist und sollte durchaus sehr subjektiv sein. Fühlt sich die gewählte Struktur für mich richtig, fühlt sie sich natürlich an? Nur wenn dies der Fall ist, wird man effektiv, weil ohne innere Widerstände, arbeiten können.
Für das input-type-Attribut sieht HTML5 viele neue Werte vor. Mit der Wahl des richtigen Wertes wird auf mobilen Geräten die passende Tastatur »getriggert«. Durch kleine Anpassungen im HTML wird die Usability von Formularen auf iPad & Co so deutlich verbessert.
Formularelemente nehmen unter allen HTML-Elementen eine besondere Rolle ein. Erst durch sie wird das Internet zum interaktiven Medium. Von daher sollten Formulare mit besonderer Sorgfalt aufgebaut werden. Erschreckend ist etwa, dass auf zahlreichen Webseiten kein label-Element verwendet wird und so eine einfache Möglichkeit ausgelassen wird, die Nutzbarkeit eines Formulars deutlich zu verbessern.
Ein kurzer Blick auf die Grundlagen
<labelfor="vorname">Vorname</label>
<inputtype="text"name="vorname"id="vorname">
<inputtype="checkbox"name="agb"id="agb">
<labelfor="agb">AGB anerkennen</label>
So sieht’s aus:
Das label ist die Beschriftung eines Formularelements und wird über die id des Formularelements (egal, ob input, select oder textarea) und dem for-Attribut im label verknüpft. Erst damit ist es Nutzern von Screenreadern möglich, ein Formular richtig zu füllen, da die Beschriftung der Felder eindeutig ist.
Nicht nur Screenreadernutzer profitieren vom korrekten Umgang mit dem label-Element. Klicken Nutzer auf die Beschriftung, dann befindet sich der Fokus im Eingabefeld. Klicken sie auf das label einer Radio- oder Checkbox, wird die Box aktiviert und bei Checkboxen beim zweiten Klick wieder deaktiviert. Bei den kleinen Radio- und Checkboxen wird über das label-Element die Klickfläche vergrößert und die Bedienbarkeit ist für alle Nutzer verbessert.
Neue Herausforderung durch SmartPhones und Tablets
Die Vergrößerung der klicksensiblen Fläche steigert die Usability der Formulare auch auf mobilen Geräten. Mit den neuen HTML5-Formular-Attributen kann die Formularbedienbarkeit auf iOS- und Android-Geräten mit wenig Aufwand zusätzlich verbessert werden.
Grundlage für die Optimierung ist die Tatsache, dass sich die Tastatur auf mobilen Geräten von den Tastaturen von Desktoprechnern und Laptops unterscheidet. Das ist für die meisten selbstverständlich, für die Optimierung eines Formulars muss man sich aber genau diese Tatsache vor Augen halten. Es sind nie alle Zeichen auf einem Blick verfügbar oder mit dem Drücken der Umschalttaste zu erreichen. Mobile Geräte bieten unterschiedliche Tastaturansichten, eine Standardansicht mit Buchstaben und den häufigsten Satzzeichen, eine weitere für Zahlen und weiteren Satz- und Sonderzeichen, eine oder mehrere Ansichten für diverse Sonderzeichen.
Bei der Optimierung steht die Wahl des richtigen type-Attributs für das input-Element im Mittelpunkt. Ziel ist immer, die richtige Tastaturansicht zu triggern und damit den Weg zum richtigen Zeichen so kurz wie möglich zu halten. Sprich: Bei jedem Formularelement gilt es, sich zu überlegen, welche Zeichen Nutzer dort eingeben werden, um dann den passenden Wert für das type-Attribut zu wählen.
Der Attributwert email sorgt dafür, dass sowohl auf iOS- als auch auf Android-Geräten die Tastatur um ein @-Zeichen ergänzt wird. Ein Wechsel zur richtigen Tastatur, bzw. die Überlegung, auf welcher Tastatur sich das @-Zeichen überhaupt befindet, ist damit hinfällig.
Tastatur mit @-Zeichen beim type-Parameter email auf dem iPad
Android zeigt zusätzlich eine Taste mit der Aufschrift .com an. Hält der Nutzer die Taste einen kurzen Moment fest, erscheinen weitere Top-Level-Domains, die je nach Android-Version und Spracheinstellung des Gerätes variieren.
Tastatur mit @-Zeichen und .com-Taste beim type-Parameter email auf Android
Hier profitieren nicht nur Nutzer mobiler Geräte. Auch bei neueren Browsern bewirkt type="email", dass die Eingabe vor dem Senden überprüft wird und eine falsche Eingabe das Absenden des Formulars verhindert (insofern diese Überprüfung durch den Browser nicht über das Attribut formnovalidate deaktiviert ist).
Fehlermeldung beim type-Parameter email im Google Chrome
Allerdings ist diese Validierung nur halbherzig, mit der Eingabe von a@b gilt die Prüfung auf eine korrekte E-Mail-Adresse als gültig. iOS selbst überprüft die Eingabe nicht.
type="tel" und type="number"
<labelfor="telefon">Telefon</label>
<inputtype="tel"name="telefon"id="telefon">
So sieht’s aus:
Soll in ein Feld eine Postleitzahl, eine Bestellmenge oder eine Telefonnummer eingegeben werden, bieten sich die type-Werte tel oder number an. Das bringt auf beiden mobilen Betriebssystemen die Zahlentastatur zur Ansicht.
Zahlentastatur beim type-Parameter tel auf dem iPad
Vor allem unter Android wird ein Zahlenblock angezeigt, der die Eingabe noch einfacher macht.
Zahlenblock beim type-Parameter tel auf Android
Während tel auch die Eingabe bestimmter Sonderzeichen erlaubt, können bei number ausschließlich Zahlen eingegeben werden. Dabei sind nicht nur ganze Zahlen zulässig, auch Fließkommazahlen können eingegeben werden.
Zahlenblock ohne Sonderzeichen beim type-Parameter number auf Android
Je nach Android-Gerät ist jedoch die Eingabe eines Kommas bzw. Punktes nicht möglich. Von daher: number sollte nur dann eingesetzt werden, wenn zu 100% sicher ist, dass eine ganze Zahl eingegeben wird, wie beispielsweise bei einer Bestellmenge. Bei einer Hausnummer, die prinzipiell noch einen Zusatz haben kann (z. B. 16a), wäre der Einsatz von number hingegen fatal.
type="url"
<labelfor="domain">Domain</label>
<inputtype="url"name="domain"id="domain">
So sieht’s aus:
Statt der normalen Buchstabentastatur werden bei type="url" auf iOS-Geräten neben den Buchstaben nur Zeichen angezeigt, die in einer URL erlaubt sind: Doppelpunkt, Slash, Bindestrich und Unterstrich oder die Space-Taste sind hier nicht zu finden.
Ebenfalls wird eine .com- bzw. .de-Taste angezeigt (je nach Spracheinstellung des Geräts), die auch hier beim Halten bzw. Hochwischen weitere Top-Level-Domains anzeigt.
Tastatur beim type-Parameter url auf dem iPad mit .com-Taste
Auf Android-Geräten triggert url leider keine spezielle Tastatur.
type="date", type="datetime", type="datetime-local", type="time" und type="month"
<labelfor="datum">Datum</label>
<inputtype="date"name="datum"id="datum">
<labelfor="zeit">Zeit</label>
<inputtype="time"name="zeit"id="zeit">
So sieht’s aus:
Anzeige eines Drehrädchen beim type-Parameter datetime auf dem iPad
Eine Reihe von Zeit bzw. Datumswerten sind date, datetime, datetime-local, time und month. Diese führen auf iPad und iPhone dazu, dass keine Tastatur, sondern das Apple-typische Drehrädchen angezeigt wird.
Ein solches Bedienelement liefert einen genormten Zeitstring an den Server, der zum Beispiel so aussieht: 2013-12-15T12:45:17Z. Dieser Zeitwert erfordert eine spezielle Verarbeitung. Da jedoch Android sowie die meisten Desktop-Browser kein zufriedenstellendes Bedienelement anbieten, sollten Zeit bzw. Datumswerte für ein input-Element nur zum Einsatz kommen, wenn eine Seite ausschließlich für Apple-Geräte erstellt oder ein Fallback für die anderen Betriebssysteme angeboten wird.
type="week" und type="color"
Lediglich der Vollständigkeit halber seien hier die Werte week und color erwähnt. Ältere Android-Versionen und iOS unterstützen diese Parameter nicht, auch bei Desktop-Browsern ist keine browserübergreifende Unterstützung gegeben, von daher sind diese Werte für den Praxiseinsatz noch nicht geeignet.
Eine Optimierung anderer Art ist die Unterdrückung der Umschalttaste. Standardmäßig wird (falls dies in den Einstellungen nicht deaktiviert wurde) die Umschalttaste aktiviert, sobald der Fokus im Feld ist, so dass die Eingabe mit einem Großbuchstaben beginnt. Was grundsätzlich eine gute Idee ist, muss nicht immer gewollt sein. Beispielsweise bei der Eingabe eines Usernamens, der wahrscheinlich bei vielen nicht mit einem Großbuchstaben beginnt.
Über autocapitalize="off" wird das automatische Aktivieren der Umschalttaste abgestellt. Allerdings ist autocapitalize kein Teil vom HTML5-Standard, sondern stammt von Apple, daher greift dieses Attribut nur auf iOS-Geräten.
Ähnlich wie bei der Umschalttaste verhält es sich mit der Autokorrektur. Bei der Eingabe eines Nutzernamens ist es eher hinderlich, wenn das Gerät Wortvorschläge macht. spellcheck="false" ist dabei valides HTML5 und unterdrückt die Autokorrektur auf Android-Geräten, autocorrect="off" ist von Apple und bewirkt den gleichen Effekt auf iPhone und iPad.
Browserkompatibilität
Nicht nur bei neuen input-type-Attributwerten, sondern generell beim Einsatz von neuen HTML5-Elementen müssen sich Webentwickler die Frage nach der Browserunterstützung stellen. Neue Strukturelemente wie section oder article müssen entweder mit div-Elementen umbaut werden oder beispielsweise über
html5shiv»aktiviert« werden,
damit diese die Darstellung im Internet Explorer 8 nicht »zerfetzen«.
Das Aktivieren neuer type-Parameter ist hingegen nicht möglich und auch nicht notwendig. Browser sind nicht dumm und können mehr, als die Standards definieren. Fehlt ein type im input-Element, oder hat type eine neuen Wert, den der Browser nicht kennt, wird ein einfaches Eingabefeld vom type="text" angezeigt. So ist bei älteren Browsern beispielsweise bei type="email" trotzdem die Eingabe einer E-Mail möglich. Neuere Browser, vor allem Nutzer mobiler Geräte, profitieren von neuen type-Parametern, da die richtige Tastatur angezeigt und das Wechseln der Tastatur überflüssig wird.
Webentwickler müssen sich allerdings im Klaren sein, dass die Wahl des richtigen type-Parameters keine Garantie für korrekte Eingaben ist. Ganz nach der alten Entwickler-Devise »All input is evil (jede Eingabe ist bösartig)«: Auch wenn bestimmte type-Werte vergeben sind, müssen alle Eingaben serverseitig auf ein richtiges Format bzw. zulässige Werte überprüft werden.
Bezüglich der Bedienbarkeit eines Formulars stellen die neuen type-Werte jedoch eine enorme Verbesserung dar! Hier ist der Einsatz von HTML5 bereits heute sinnvoll.
Die alten Internet Explorer bis Version 8 haben viele Techniken nicht implementiert, die Webworker heute gerne und oft nutzen. In solchen Fällen kann der Präprozessor SASS hilfreich sein, um den alten IE – ohne viel zusätzliche Arbeit – eine Extrawurst zu braten.
Die Nutzung moderner Techniken im Frontend ist nicht mehr ungewöhnlich. Die meisten dieser Techniken werden von älteren IE (bis inklusive Version 8) nicht unterstützt. Manche haben allerdings ein IE-spezifisches Pendant. Deshalb sind Webworker immer wieder in der Situation, oldIE (IE 8 und früher) eigene Styles zuweisen zu wollen.
Wollt ihr euch nicht nur auf Hacks verlassen, könnt ihr einen Präprozessor wie Sass für diese Zwecke nutzen. Dadurch befreit ihr gleichzeitig das CSS für die richtigen Browser von altem Ballast und Hacks. Das Prinzip ist dabei einfach.
Ich lass Dich nicht rein
Als allererstes müsst ihr verhindern, dass oldIE das gleiche Stylesheet liest wie alle modernen Browser. Denn schließlich möchtet ihr nicht ein globales CSS durch ein IE-spezifisches ergänzen, ihr möchtet zwei getrennte Welten schaffen. Dafür bindet ihr das CSS folgendermassen ein:
<!-- Dieses CSS wird vom oldIE definitiv nicht gelesen -->
<link rel="stylesheet" href="css/styles.css" media="all and (min-width: 0px)">
<!--[if lte IE 8]>
<link rel="stylesheet" href="css/oldie.css">
<![endif]-->
Zuerst verlinkt ihr styles.css mit einer Media Query, die den alten IE davon abhält, diese Datei herunterzuladen. Danach verlinkt ihr für oldIE ein spezielles CSS innerhalb eines Conditional Comment. Getrennte CSS-Dateien für IE7 und IE8 solltet ihr vermeiden, sie würden den Pflegeaufwand unnötig erhöhen. Zudem könnt ihr zwischen beiden Versionen prima mit dem Star-Plus-Hack unterscheiden. Und nicht zuletzt werden die IE7-Nutzer immer weniger, und nur der IE8 wird noch ein Weilchen als Pflegefall verbleiben.
Auf diese Weise weist ihr zwei CSS-Dateien sauber voneinander getrennt zu. Doch eigentlich wollt ihr effektiv nur an einer CSS-Datei arbeiten. Deshalb müsst ihr den nächsten Schritt tun.
Variablen
Die Unterscheidung zwischen »für oldIE« und »für richtige Browser« kann auf mehreren Wegen getroffen werden. Die gängigste Methode ist die Nutzung einer Variablen.
Ihr erstellt zwei SCSS-Dateien – styles.scss und oldie.scss –, in die ihr eure eigentlichen Sass-Dateien (die Partials) importiert. Am Anfang der beiden Dateien definiert ihr eine Variable in zwei Ausprägungen. Im Falle der oldie.scss schreibt ihr isoldIE: true; und im Falle der styles.scss schreibt ihr isoldIE: false.
Aufteilen in Portionen
Die eigentliche Arbeit geschieht dann nicht in diesen beiden eben genannten Dateien, sondern in den Partials. Dabei kann auch einmal eine spezielle oldIE-Datei importiert werden, im Grundsatz sollen aber alle Einzeldateien in die beiden zentralen Dateien importiert werden.
Variablennutzung
Die Variablen entfalten ihre Wirkung in Mixins und in einzelnen Regeln. Sie werden dabei mit @if-Bedingungen in den Code eingeflochten. Dadurch werden die betreffenden Codeteile nur ausgegeben, wenn die Bedingung zutrifft. Ein einfaches Beispiel ist ein Mixin, das oldIE einen Filter zuweist, der dem CSS3-Boxschatten recht nahe kommt:
Da nun am Anfang der beiden zentralen Stylesheets die Variable $isoldIE steht, kann dementsprechend dieses Mixin abgearbeitet werden. @if $isoldIE ist gleichbedeutend mit @if $isoldIE == true, sodass der erste Teil des Mixins nur dann ausgegeben wird, wenn es über die Datei oldie.scss aufgerufen wird.
Nicht nur im Mixin
Was im Mixin funktioniert, kann natürlich auch in normalen Regeln angewendet werden. Die Syntax ist einfach zu merken und schnell geschrieben. Da insbesondere ältere IE ein fürchterliches Schriftrendering haben, könnt ihr diesen eine andere Schrift für alle Überschriften zuweisen, als allen anderen Browsern:
Oder ihr schreibt eine Alternative für moderne Selektoren. Irgendwann könnt ihr diesen Teil des Codes dann entfernen, wenn der letzte IE8 endlich den Weg alles Irdischen gegangen ist:
.footerlinks{
// das folgende Mixin formatiert Links horizontal
@include inline-list;
@if $isoldIE == true {
li {
border-left: 1pxsolid#666;
padding-left: 10px;
margin-left: 10px;
&:first-child{
border-left: none;
padding-left: 0;
margin-left: 0;
}
}
}@else {
li:not(:first-child){
border-left: 1pxsolid#666;
padding-left: 10px;
margin-left: 10px;
}
}
}
Fazit
Mit einem Präprozessor wie Sass könnt ihr prima an einer einzelnen Codebasis arbeiten, aber zwei unterschiedliche Varianten ausgeben. So könnt ihr den Schwächen der alten IE entgegenarbeiten, ohne dass moderne Browser mit zusätzlichem Code behelligt werden müssen.
Wie sieht der normale Tag eines selbstständigen Webdesigners aus? Darauf können auch wir pauschal keine Antwort geben. Klar ist nur, dass öde Routine nur selten dazugehört. Oft sind es die kleinen Tücken der Projektarbeit, die für ereignisreiche Stunden am Rechner sorgen. Heute gewährt uns Nils Pooker einen Blick in den Ablauf eines nicht ganz ernst gemeinten »Worst-Case-Arbeitstages«.
7.00 Uhr
Traum gehabt: Adobe-Entwickler stieg durchs Fenster in mein Büro, installierte etwas auf meinem Rechner und stieg hämisch lachend wieder hinaus. Schweißgebadet aufgewacht. Immerhin: heute ist Launch von Firma Meierhoff.
7.10 Uhr
Gut: Der Kaffee ist heiß, für Anrufe ist es zu früh. Schlecht: E-Mail-Eingänge überflogen.
Meierhoffs Mail um 23.18 Uhr. »am rechner? schicke pdf, muss noch rein.« Kein Anhang. Keine weitere Mail. PDF? Denke an den Adobe-Mann aus dem Albtraum.
Kunde Clausen will mein Angebot lesen. »Wir wollen das Redaktionssystem mit großem Funktionsumfang. Frage: Wie öffne ich Ihren Anhang?« Brauche sofort eine Zigarette.
7.20 Uhr
Kanzlei Trammer: »Dieses Jimdo ist uns doch zu kompliziert. Ein Mandant hat uns Typo3 empfohlen, ist das einfacher?« Ruhig bleiben.
Firma Klöbner? Wer war das noch? »Sie hatten uns 2002 eine Website erstellt. Kann man die für mobile Geräte optimieren?« Komplette Löschung? Zugang sperren? Abschalten der CSS-Datei?
Markiere die Mail mit »Ist Werbung«. Erledigt.
Sieh’ an, Kunde Lüdermann schickt das Foto für die Einzelansicht des Teams. »Größer, wie gewünscht!« 400 x 230 Pixel. Spaß muss sein? Kann ich auch: Photoshop > Bildgröße > Pixelwiederholung. Online.
Im Schrank stünde noch der Panama-Rum. Nein, zu früh. Zigarette.
7.50 Uhr
Vor dem nächsten Kaffee eine letzte Mail lesen. Hach, der nette und dankbare Herr Müller, also Erfreuliches. Vermutlich eine kleine Änderung an seiner statischen Site. »Wir hätten gern Suchfunktion, Aktuellbereiche, ein Blog und mehrere Formulare.«
Mein Blick fällt auf Spiegel online. Wieder Amoklauf in den USA. Kurze Recherche. Nein, war weder ein Webdesigner noch ein Entwickler.
7.55 Uhr
Kaffee in ausreichend großer Entfernung zum Schrank getrunken. Hoffe auf Ruhe für den Launch.
Pling! Mail von Meierhoff. »pdf anbei. hochauflösend.« Endlich. Hochauflösend? PDF mit 4 MB. Denke an den Adobe-Mann. In der Hoffnung auf viele Bilder falte ich beim Öffnen des Acrobats instinktiv die Hände.
Nur Text, eingescannt und als PDF gespeichert. Abtippen? Mail schreiben?
Entscheide mich für den Schrank. Oh, wie schön ist Panama.
8.15 Uhr
Gut gelaunt zurück am Rechner.
Telefon. Anruf der Agentur von Kunde Clausen: »Könnten Sie uns aus der Vorlage einen Dummy erstellen?« »Einen Klickdummy als HTML-Prototypen?« »Ach, das geht mit Photoshop?«
Erkläre das genauer und denke über die Vorteile der Waffengesetze in den USA nach.
8.25 Uhr
Anruf von Meierhoffs Assistentin. »Auf der Startseite steht noch ein Wort alleine in der letzten Zeile, das soll da weg.« »Das ist HTML und nicht zu verhindern.« »Natürlich! Blocksatz und Tabulator, geht sogar in Word!«
Erkläre das genauer und denke über eine Auswanderung in die USA nach.
Hole mir was zu trinken, damit die Zigarette nicht so trocken schmeckt. Die Schranktür kann auch offen bleiben.
8.55 Uhr
Telefon. Meierhoff höchstpersönlich. Ich melde mich noch einigermaßen deutlich. »Da ist was zerschossen!« »Hm. Welchen Browser benutzen Sie?« »Windows!« »Nein, das Programm, mit dem Sie ins Internet gehen. Am Bildschirmrand in der Menüleiste, ist da ein Symbol, vielleicht ein blaues ›e‹?« »Moment. Ah, hier. Da steht ›Samsung‹.«
Genehmige mir einen sehr großen Schluck. Nach Telefonat mit dem Praktikanten, der sich das mal angesehen hat, lasse ich mich wieder zu Meierhoff durchstellen und versuche zu erklären, dass die Kombination aus sehr groß eingestellter Schrift und dem IE6 bei stark verkleinertem Browserfenster zu leichten optischen Irritationen führen kann. Erklärungsversuch scheitert. Trinke noch etwas mehr und frage nach den PDF-Inhalten als Word-Datei. Klar, haben die nicht mehr. Erwähne dann leichtsinnig den Begriff »OCR-Texterkennung«. »OCR? Schade, unser Scanner ist leider von Epson.«
Vor dem Abtippen zwei Zigaretten und mal eine Kleinigkeit trinken. Auswanderung nach Panama wäre auch eine Option. Besser das Telefon in die Brusttasche stecken. Habe das Glas im Büro vergessen. Egal, geht auch aus der Flasche.
9.45 Uhr
Panama macht keine gute Laune mehr.
Drei Anschläge, dann schmiert Acrobat ab. Der Adobe-Mann? Hangle mich geschickt mit den Händen am Schreibtisch entlang und stoße nur zweimal gegen Möbelstücke. Blicke nach draußen, aber weit und breit niemand zu sehen. Jetzt den Rückweg antreten.
10.25 Uhr
Scheiß Turnschuhe, nicht gesehen. War dann auch keine gute Idee zu versuchen, an einem Drehstuhl hochzukraxeln, nicht zu empfehlen, dauert ewig. Bleibe jetzt sitzen und hoffe auf ausdauernde Blase. Dumpfe Töne. Augen und Ohren versuchen, die Geräuschquelle zu identifizieren. Da! Zwei Telefone auf dem Boden zwischen mir und dem Fenster? Ach nee, doch nur eines. Nicht noch einmal aufstehen, warte lieber auf E-Mails.
Klick, Acrobat öffnet sich wieder, ich weiche automatisch zurück. Jetzt behutsam tippen. Schnell geht eh nicht mehr. Entdecke noch einen großen Rest in der Flasche. Puh, Panama.
16.30 Uhr
Langsam kann ich wieder klar denken, war wohl kurz weggenickt. Zwei getippte Seiten, Tastatur scheint kaputt zu sein, Text ist kaum zu entziffern. Fünf Anrufe in Abwesenheit auf der Basisstation. Nanu, so viele Browser-Tabs? Ein Formular zur Bewerbung bei der CIA? Eine Seite mit Infos zur Auswanderung, ein Tab mit irgendeiner »Rifle Association« und ein Tab mit Google-Suche nach »Kopfschmerzen Chemtrails Adobe«? Scheiß Spam.
Blicke auf den Posteingang. Ups, Mail von Meierhoff vor zwei Stunden: »wo sind sie, pdf hat sich erledigt, bitte sofort online schalten!!!!« Öffne das Backend des CMS. Klick. Launch.
Mail an Meierhoff: »Online. Sorry, habe zur Zeit Panama-Grippe.«
16.55 Uhr
Mail von Meierhoff: »na endlich. logo muss vier millimeter weiter nach links, habe das mit lineal nachgemessen!!! wieso sehe ich auf meinem alten laptop die runden ecken und schatten nicht, wo sind die??? assistentin hat alte www-adresse noch im google gefunden, bitte da mal schnell anrufen wg. änderung. gute besserung.«
Der Rechner lässt sich nicht gut tragen. Draußen zünde ich mir eine Zigarette an und atme tief durch. Wundervoll, diese Ruhe. Die ersten Schneeflocken, friedlich und sanft bedecken sie den winterlichen Rasen. Ich drücke auf den Garagenöffner. Da drüben, irgendwo hinter den Fahrrädern, da müsste der Vorschlaghammer liegen.
RRRING!
Wache schweißgebadet auf. Gehe ins Büro an den Rechner und öffne das Backend des CMS von Meierhoff. Klick. Launch. Schalte den Rechner wieder aus und tippe eine SMS an Meierhoff: »Site ist freigeschaltet, kann heute leider keine Mails empfangen.«
Usability Engineering: Arbeiten mit Nutzungsanforderungen
Um interaktive Systeme mit hoher Usability zu entwickeln, ist es notwendig, die Nutzungsanforderungen zu kennen und in geeignete technische Lösungen umzusetzen. Dabei ist es sehr einfach, an die richtigen Anforderungen zu gelangen: Man stellt Nutzern die richtigen Fragen und hört aufmerksam zu.
Der benutzerzentrierte Gestaltungsprozess
Usability ist definiert als »Ausmaß, in dem ein interaktives System durch bestimmte Benutzer in einem bestimmten Nutzungskontext genutzt werden kann, um festgelegte Ziele effektiv, effizient und zufriedenstellend zu erreichen« (ISO 9241-11). Hohe Usability lässt sich planen und erzielen, wenn in allen Phasen der Entwicklung des interaktiven Systems der Benutzer im Mittelpunkt steht. Man spricht dabei von einem benutzerzentrierten Gestaltungsprozess, der aus vier miteinander verbundenen Aktivitäten besteht (siehe Abbildung 1).
Abbildung 1: Benutzerzentrierter Gestaltungsprozess (nach ISO 9241-210)
Die beiden ersten Aktivitäten nach der Planung lassen sich unter dem Stichwort »benutzerzentrierte Analyse« zusammenfassen; darauf basierend erfolgt die »benutzerzentrierte Gestaltung«; den Abschluss einer Iteration bildet die »benutzerzentrierte Evaluation«.
Warum überhaupt analysieren?
Eine Websites und Web-Anwendungen kann nur dann erfolgreich sein, wenn von Beginn an klar ist, welches Problem sie eigentlich lösen soll, und wenn jede einzelne Anforderung aus der Sicht des Nutzers begründet ist. Sonst kommt es zu fehlenden oder überflüssigen Funktionen, wodurch Nutzer vergrault (und die Kosten gesteigert) werden und das Projekt scheitert. Das wurde in der Vergangenheit durch zahlreiche Beispiele bestätigt, besonders drastisch beispielsweise bei der Ablösung AltaVistas durch Google.
AltaVista war bis ins Jahr 1999 neben HotBot die bekannteste Volltext-Suchmaschine der Welt. Ende der 1990er veränderte AltaVista seine strategische Ausrichtung und entwickelte sich von einer Suchmaschine zu einem Portal mit Nachrichten, E-Mail und Einkaufsangeboten (siehe Abbildung 2). AltaVista versuchte damit, mit Yahoo! zu konkurrieren, war damit aber nahezu erfolglos. Im Suchmaschinenmarkt wurde AltaVista währenddessen ziemlich schnell von Google überholt. Das lag vor allem daran, dass Google sich konsequent auf die primären Anforderungen der Nutzer ausgerichtet hatte: Das User Interface beschränkte sich auf Wesentliche, nämlich das Suchfeld und die Anzeige der Suchergebnisse. Bei den damals noch üblichen langsamen Internet-Verbindungen brachte das den Suchmaschinennutzern erhebliche Vorteile. AltaVista wurde nach mehreren Übernahmen von Yahoo! gekauft und verlor bis zu seiner Schließung im Juli dieses Jahres mehr und mehr an Bedeutung. Google hingegen gehört seit Jahren zu den wertvollsten Marken der Welt.
Abbildung 2: AltaVista und Google 1999 (Quelle: archive.org)
Anforderungen konsequent aus der Perspektive der Benutzer zu berücksichtigen, ist die zentrale Grundlage erfolgreicher Projekte und kann entscheidend sein für den Erfolg eines gesamten Unternehmens. Der Ansatz der benutzerzentrierten Analyse stellt sicher, dass diese sogenannten Nutzungsanforderungen systematisch ermittelt, dokumentiert, geprüft und verwaltet werden.
Den Nutzungskontext verstehen und beschreiben
Wer die oben genannte Definition von Usability verinnerlicht hat, wird aufhorchen, wenn er Aussagen hört wie »Die Usability dieser Anwendung ist schlecht« und sich fragen: Schlecht für wen? Schlecht unter welchen Rahmenbedingungen? Oder mit den Worten eines Usability Engineers: Schlecht für welchen Nutzungskontext?
Der Nutzungskontext eines interaktiven Systems wird beschrieben durch die Benutzer, deren Aufgaben und Arbeitsmittel (Hardware, Software und Materialien) sowie die Umgebung, in der sie mit dem interaktiven System arbeiten (ISO 9241-11), siehe Abbildung 3.
Abbildung 3: Elemente des Nutzungskontexts eines interaktiven Systems
Was bedeutet das genau, beispielsweise für eine Web-Anwendung zur Erstellung von Terminumfragen wie Doodle?
Benutzer sind Personen, die eine Umfrage erstellen oder daran teilnehmen wollen. Zumindest der ersten Gruppe lässt sich eine gewisse IT- bzw. Online-Affinität unterstellen.
Ziele und Arbeitsaufgaben: Eine Umfrage erstellen und andere dazu einladen; an einer Umfrage teilnehmen; Umfrageergebnisse einsehen.
Arbeitsmittel sind primär ein Webbrowser und ein Gerät, auf dem dieser läuft, beispielsweise ein Notebook oder ein Smartphone. Arbeitsmittel sind aber auch ein Kalender und ein Adressbuch.
Über die Umgebung lässt sich am wenigsten sagen. Termine werden überall vereinbart, daher ist ein mobiler Kontext, vielleicht unter widrigen Sicht- und akustischen Bedingungen, genauso wahrscheinlich wie eine Nutzung im Büro auf einem 24-Zoll-Display.
Klingt diese Nutzungskontextbeschreibung überzeugend? Sie wurde wohlüberlegt und gewissenhaft verfasst. Aus Sicht eines Usability Engineers ist sie dennoch wertlos – sie basiert vollständig auf Annahmen und ist ohne Benutzerbeteiligung entstanden.
Bei überschaubaren Websites und Web-Anwendungen mit bekannter Aufgabenstellung, reicht es aus, die Beschreibung des Nutzungskontexts mit echten Benutzern zu diskutieren und zu validieren. Beispielsweise bei der Website des örtlichen Zahnarztes oder eben einem Online-Terminfinder. Bei komplexen interaktiven Systemen hingegen oder solchen, die Arbeitsaufgaben einer unbekannten Fachdomäne abbilden, ist es unabdingbar, Interviews mit Benutzern zu führen und zu dokumentieren. Folgende Leitfragen können dabei zur Orientierung dienen:
Welche Aufgaben führen Sie mit dem System durch?
Wie häufig fallen die einzelnen Aufgaben an? Welche führen Sie häufig durch, welche eher selten?
Gibt es eine bestimmte Reihenfolge, in der Sie die Aufgaben abarbeiten?
Sind zur Lösung von Aufgaben Dialogschritte oder Eingaben notwendig, die Sie eigentlich nicht benötigen?
Wo kann etwas schief gehen? Wie bemerken Sie das?
Arbeiten Sie mit jemandem über das System zusammen? Wie läuft die Zusammenarbeit ab?
Macht Ihnen die Nutzung des Systems Spaß?
Welche besonderen Stärken hat die derzeitige Lösung?
Welche besonderen Schwächen hat die derzeitige Lösung?
Das Ziel ist es, zusammen mit den beteiligten Benutzern ein gemeinsames Verständnis des Kontexts und der Aufgaben zu entwickeln und darin deren Erfordernisse zu erkennen.
Nutzungsanforderungen spezifizieren
Erfordernisse beschreiben, welches Ziel ein Benutzer erreichen will und welche Voraussetzung dafür erfüllt sein muss. Sie sind aus der Sicht des Nutzers und vollkommen systemneutral formuliert, das heißt sie geben keine technischen Details vor.
Einige Erfordernisse sind offensichtlich und ergeben sich direkt aus der Aufgabe, beispielsweise das folgende Erfordernis für das Beispiel »Online-Terminfinder«:
»Ein Teilnehmer einer Terminumfrage (Benutzer) muss wissen, welche Termine angeboten werden (Voraussetzung), um bei der Teilnahme an der Umfrage (Nutzungskontext) eine Auswahl treffen zu können (Ziel).«
Andere Erfordernisse ergeben sich erst dann, wenn der Usability Engineer genau zuhört, wenn Nutzer erzählen, was sie tun oder worauf sie achten, wenn sie ihrer Arbeitsaufgabe nachgehen, und wenn er gezielt nachfragt. Beispiele dafür könnten sein:
»Ein Ersteller einer Terminumfrage muss einsehen können, welche Personen der Einladung zwar gefolgt sind, aber noch keine Angaben gemacht haben, um explizit nachfragen zu können, ob diese kein Interesse an der Veranstaltung generell oder nur an keinem Termin Zeit haben.«
»Ein Teilnehmer einer Terminumfrage muss wissen, welche Termine welche anderen Teilnehmer angegeben haben, um bei der Teilnahme an der Umfrage die Termine angeben zu können, die bevorzugte Personen ebenfalls gewählt haben.«
Alle erkannten Erfordernisse werden in einem Bericht gesammelt, der dem nächsten Schritt zugrunde liegt, der Spezifikation der Nutzungsanforderungen.
Nutzungsanforderungen beschreiben eine erforderliche Leistung oder Aktion eines Benutzers während er eine Aufgabe an einem interaktiven System durchführt. Aus dem ersten Erfordernis des oben genannten Beispiels lassen sich zwei Nutzungsanforderungen ableiten:
»Der Nutzer muss am System erkennen können, welche Termine angeboten werden.«
»Der Nutzer muss am System die Termine auswählen können, an denen er teilnehmen will.«
Die folgenden (zusätzlichen) Nutzungsanforderungen ergeben sich aus den beiden nächsten Erfordernissen:
»Der Nutzer muss am System erkennen können, welche Personen der Einladung bereits gefolgt sind.«
»Der Nutzer muss am System die bisherigen Umfrageergebnisse detailliert einsehen können, also welcher Teilnehmer welche Termine angegeben hat.«
»Der Nutzer muss am System die bisherigen Umfrageergebnisse einsehen können, bevor er selbst an der Umfrage teilnimmt.«
Je nach Größe und Komplexität des interaktiven Systems umfasst eine Nutzungsanforderungsspezifikation eine Handvoll bis viele Hundert Nutzungsanforderungen. Aus Nutzersicht ist das System damit vollständig beschrieben. Die Phase der benutzerzentrierten Analyse ist abgeschlossen.
Was man nun damit anfängt, verrät morgen der zweite Teil dieses Artikels, der zeigt, wie ihr benutzerzentrierte Analysen in der Praxis anwenden könnt.
Usability Engineering: Benutzerzentrierte Analysen in der Praxis
Die benutzerzentrierte Analyse hilft dabei, Websites und Web-Anwendungen so zu gestalten, dass sie nützlich und effizient sind. Die notwendigen Informationen werden über Interviews mit den Benutzern erhoben – das kann aufwendig sein. Für gewöhnliche Websites genügt es, auf eigene Erfahrungen zurückzugreifen, diese sollten aber vernünftig erfasst und hin und wieder mit echten Nutzern abgeglichen werden.
Nutzungsanforderungen bilden die Grundlage für die Gestaltung
In den ersten beiden Phasen des benutzerzentrierten Gestaltungsprozesses (Abbildung 1) geht es darum, den Nutzungskontext zu beschreiben und Nutzungsanforderungen zu spezifizieren. In der dritten Phase werden darauf basierend Lösungen entworfen. Dabei finden im Wesentlichen zwei Aktivitäten statt: das Interaktionsdesign sowie die Gestaltung des User Interfaces.
Abbildung 1: Benutzerzentrierter Gestaltungsprozess (nach ISO 9241-210)
Das Interaktionsdesign beschreibt das Zusammenspiel zwischen den Eingaben des Nutzers und den Ausgaben des Systems, während der Nutzer mit dem System arbeitet, um seine Aufgaben zu erledigen. Das User Interface wiederum besteht nach ISO 9241-210 aus allen Bestandteilen eines interaktiven Systems, die Informationen und Steuerelemente zur Verfügung stellen, die der Benutzer benötigt, um seine Aufgaben mit dem interaktiven System zu erledigen. Das bedeutet, dass alle Elemente, die er dafür nicht benötigt, im User Interface nichts zu suchen haben.
Letztlich dreht sich auch hier wieder alles um den Benutzer und seine Aufgaben. Beides gehört zum Nutzungskontext und findet sich in den Erfordernissen und Nutzungsanforderungen wieder, die dem Designer damit klar vorgeben, was sie zu gestalten haben (und was nicht).
Auf der anderen Seite lassen Nutzungsanforderungen Designern aufgrund der Art, wie sie formuliert sind, auch viele Freiheiten. Sie beschreiben zwar, wie ein Nutzer mit einem System interagiert, implizieren aber keine Lösung. Folgende Gegenüberstellung macht den Unterschied deutlich:
»Der Nutzer muss über das System Kontakt zu einem Ansprechpartner aufnehmen können.«
»Das System muss dem Nutzer ein Kontaktformular bereitstellen, das in einem Popup-Fenster eingeblendet wird.«
Die erste Formulierung ist eine Nutzungsanforderung. Sie macht dem Designer keine Vorgaben und überlässt es ihm, die Steuerelemente und Informationen auszuwählen und anzubieten, die aus seiner Sicht die Aufgabenerfüllung bestmöglich unterstützen. Die zweite Formulierung ist eine Systemanforderung und beschreibt bereits eine konkrete Lösung, aber sicherlich nicht die beste. Im mobilen Kontext wäre vielleicht eine Telefonnummer wünschenswert, aber die konkret formulierte Anforderung bietet keinen Raum für eine derartige Idee.
Anwendbarkeit der benutzerzentrierten Analyse in der Praxis
Interviews mit Benutzern führen, den Nutzungskontext beschreiben, Erfordernisse erkennen und dokumentieren – das alles, um zu einer möglichst vollständigen Spezifikation der Nutzungsanforderungen zu gelangen? In welchen Projekten lässt sich das wirtschaftlich durchführen? Lohnt sich der Aufwand bei einer Website, über die der örtliche Zahnarzt auf sein Angebot aufmerksam machen möchte, oder über die eine Ferienwohnung präsentiert und zur Reservierung angeboten werden soll? Ist es sinnvoll, Nutzungsanforderungen zu spezifizieren, wenn es darum geht, kleine Web-Anwendungen zu entwickeln wie beispielsweise ein einfaches Tool zur Arbeitszeiterfassung oder einen Online-Terminfinder? Die Antwort lautet in allen Fällen: Ja! Man muss nur pragmatisch vorgehen.
Bei den gerade genannten Beispielen gehört vermutlich jeder Webworker selbst zur Gruppe der potenziellen Nutzer und kann daher auf Basis der eigenen Erfahrungen und Erfordernisse versuchen, den Nutzungskontext zu beschreiben. Daraus ergibt sich ein erster Satz von Nutzungsanforderungen, der allerdings noch mit Vorsicht zu genießen ist. Die Annahmen müssen validiert und gegebenenfalls korrigiert und ergänzt werden.
Der Auftraggeber eignet sich dafür im Allgemeinen nicht. Häufig gehört er selbst zu keiner (echten) Benutzergruppe des Systems oder ist fachlich vorbelastet. Ein Zahnarzt besucht die Website eines anderen Zahnarztes aus ganz anderen Gründen als Personen mit Zahnschmerzen auf der Suche nach Hilfe und einem Termin.
Auch der Blick auf vergleichbare Websites und Anwendungen ist nicht hilfreich, denn was dort zu sehen ist, sind Lösungen. In der Analyse sucht man aber nach Problemen (Arbeitsaufgaben) und den tatsächlichen Anforderungen der Nutzer. Was lässt sich beispielsweise daraus schließen, wenn auf vier von fünf analysierten Ferienwohnungen-Websites eine Anzeige des örtlichen Wetters zu sehen ist? Braucht man das? Warum? Anderes gefragt: Gibt es dafür ein Erfordernis? »Der Besucher der Website muss wissen, wie das aktuelle Wetter am Ort der Ferienwohnung ist, um« – tja, um was? Vermutlich gibt es dafür kein Erfordernis und diese Funktion ist unnötig.
Die einzige Möglichkeit, Annahmen zu validieren, bieten Interviews mit anderen (potenziellen) Benutzern. An die ist relativ einfach heranzukommen, wenn das Ziel der Website oder Web-Anwendung allgemeinverständlich ist. Vermutlich eignet sich fast jeder. Am Beispiel der Ferienwohnung-Website reichen zwei Fragen, um herauszufinden, ob jemand zur avisierten Benutzergruppe gehört oder nicht: »Machen Sie Urlaub in Ferienwohnungen? Würden Sie eine Ferienwohnung über das Internet reservieren?« Wer diese beiden Fragen mit »Ja« beantwortet, gehört dazu und eignet sich für eine Befragung (die zudem vermutlich nicht lange dauert). Häufig kommt bereits nach zwei oder drei Gesprächen nichts Neues mehr. Wenn es mehr als eine Benutzergruppe gibt, beispielsweise Ersteller von Terminumfragen und Teilnehmer an Terminumfragen, dann sind entsprechend mehr Interviews notwendig.
Auf diese Weise können Webworker die Annahmen, die sie beim ersten Entwurf der Nutzungskontextbeschreibung getroffen haben, bestätigen oder widerlegen sowie durch neue Erkenntnisse ergänzen. Als Ergebnis erhalten sie eine vollständige und validierte Nutzungskontextbeschreibung und damit
Informationen über die (verschiedenen) Benutzer des interaktiven Systems sowie
deren Ziele, Arbeitsaufgaben und Aufgabenabfolgen und somit eine Beschreibung des Zwecks des Systems;
für jede Nutzungsanforderung eine Begründung aus Benutzersicht in Form eines oder mehrerer Erfordernisse und dadurch Hinweise darauf, welche Funktionen unnötig komplex oder gar überflüssig sind;
Informationen über die Rahmenbedingungen, unter denen das System eingesetzt wird;
eine Grundlage für die weiteren Arbeitsschritte im Projektverlauf, vor allem in Bezug auf die Gestaltung;
eine Basis für Inspektionsverfahren in der Phase der benutzerzentrierten Evaluation (dabei dient die Liste der Nutzungsanforderungen als Checkliste, anhand der überprüft wird, ob das System effektiv ist, also alle Nutzungsanforderungen erfüllt);
eine professionelle Basis für die Angebotserstellung gegenüber den Kunden sowie – last but noch least –
eine Grundlage für die benutzerzentrierte Analyse bei folgenden, ähnlichen Projekten.
Und dafür lohnt es sich doch, ein wenig Zeit bei Gesprächen mit seinen Nutzern zu verbringen, oder?
Ein neues Projekt steht an. Für die Web-Applikation wird Modernizr, jQuery, normalize.css und Handlebars sowie das jQuery Plugin lazyload benötigt. Die Komponenten sucht sich der Frontendler auf den einzelnen Webseiten oder Github zusammen und lädt die neusten Versionen in den Projektordner. Eine nach der anderen, so wurde das früher gemacht. Heute gibt es Bower, ein Open-Source-Projekt von Twitter. Und Bower macht das mit nur einem Befehl im Terminal. bower install...
Das Stichwort heißt Package Management in Verbindung mit der Workflow-Optimierung eines Frontendlers. Und vielleicht auch noch Spaß-mit-der-Konsole. Auf jeden Fall lohnt sich ein Blick auf das neue Tool, das von den internationalen Stars der Szene so eifrig angepriesen wird. Und nicht ohne Grund.
Das Logo von Bower
I've got the Bower
Bower? Bower ist Englisch und bedeutet Vogelkäfig oder Gartenlaube. Das Logo zeigt einen Vogel mit einem Blatt im Schnabel und soll wohl die einfache Handhabung zum Ausdruck bringen. Und relativ einfach funktioniert es auch, aber zuerst wird Bower benötigt.
Bower läuft mit node.js und dem Node Package Manager, kurz npm, sowie Git. Also muss zuerst node.js von der Homepage installiert werden und das bringt den Package Manager npm direkt mit. Über das Terminal, die Konsole, die Shell oder die Eingabeaufforderung (je nach OS) wird Bower danach installiert. Mit folgender Eingabe:
npm install –g bower
npm aktiviert den Node Package Manager. Install –g bower installiert dann global, also auf dem Rechner und nicht nur in einem definierten Ordner, den Bower Package Manager.
Da Bower die angeforderten Packages ausschließlich über Github bezieht, muss vor dem ersten Einsatz unbedingt noch Git auf dem Rechner installiert werden. Achtung bei Windows, hier bei der Installation unbedingt darauf achten, dass Git auf der Windows Command Prompt, also der Eingabeaufforderung angewendet werden kann.
Soviel zu den Vorbereitungen.
Die Arbeit mit der Konsole
Bower kann auf drei verschiedene Arten eingesetzt werden: Mit einer Direktaufforderung über das Terminal, durch Aufruf der Konfigurationsdateien im Repository oder über die programmatische API.
Über die Eingabeaufforderung springt der Developer zu einem leeren Ordner. Das geht über den Befehl cd (change directory) und der Eingabe des Pfads zum Ordner. Oder in Windows viel einfacher über die Adressleiste des Explorers, mit der Eingabe cmd. Mit dem Befehl bower install jquery in der Konsole kopiert Bower dann die neuste jQuery-Version (bis dato Version 2.0.3) von Github, erzeugt im referenzierten Verzeichnis automatisch einen neuen Ordner namens »bower_components« und legt in diesem wiederum den Ordner »jquery« mit allen integrierten Dateien ab. Das sieht dann so aus:
bower install jquery – links die Ausgabe der Konsole, rechts der erzeugte Ordner mit Inhalt
Neben dem gewünschten Package kann auch explizit eine Versionsnummer angegeben werden. Also im Fall von jQuery z. B. bower install jquery#1.10.2. Aber die Direkteingabe kann noch ein bisschen mehr. Mit bower search werden alle registrierten Packages für Bower aufgelistet und mit bower uninstall jquery lokal installierte Packages (in diesem Beispiel jQuery) wieder deinstalliert. bower update jquery aktualisiert zur neusten Version von jQuery.
Eine sehr hilfreiche Aufforderung ist bower init, mit der sich eine bower.json-Konfigurationsdatei Schritt für Schritt auf Grundlage des vorhandenen Repositorys manuell über die Konsole erstellen lässt. Der Codeblock etwas weiter unten zeigt welche Properties über bower init abgefragt werden.
Auf ein besonderes Feature, bower register für das Registrieren von eigens hergestellten Packages für Bower, gehe ich am Ende des Artikels noch einmal kurz ein, denn dazu wird zuerst eine Konfigurationsdatei gebraucht.
Die Konfiguration von Bower
Die Integration vom Bower-Package-Manager, z. B. in ein Boilerplate, läuft über die Konfiguration mit bower.json und der .bowerrc-Datei.
Alle Packages, die für ein Projekt benötigt werden, werden in einem JSON-File mit dem Dateinamen bower im Repository vorkonfiguriert. Das erspart die doch recht mühselige Einzel-Installation über die Konsole. Die bower.json-Datei setzt sich folgendermaßen zusammen:
{
"name" : "Mein Packagename",
"version" : "Meine Packageversion, z. B. 1.0.0",
"authors" : [
"Autor 01 <autor01@email.de>"
],
"description" : "Beschreibung des Packages",
"keywords" : [
"Suchbegriff 01",
"Suchbegriff 02"
],
"license" : "Lizenzangabe, z. B. MIT",
"homepage" : "Homepage zum Package, falls vorhanden",
"private" : Nur für den privaten gebrauch? true oder false,
"ignore" : [
"**/.*",
"Datei, die nicht mitgepackt werden soll 01",
"Datei, die nicht mitgepackt werden soll 02..."
],
"dependencies" : {
"Package, das benötigt wird 01" : "Versionsnummer",
"Package, das benötigt wird 02" : "Versionsnummer",
"Package, das benötigt wird 03" : "Versionsnummer",
},
"devDependencies" : {
"Datei, die nur zur Entwicklung des Packages benötigt wird 01" : "Versionsnummer",
"Datei, die nur zur Entwicklung des Packages benötigt wird 02" : "Versionsnummer",
"Datei, die nur zur Entwicklung des Packages benötigt wird 03" : "Versionsnummer"
}
}
bower.json mit allen relevanten Properties
Diese Konfiguration kann zum einen zur Registrierung eines Packages und aller benötigten Dateien (den Dependencies) für Bower auf Github dienen, zum anderen aber auch um benötigte Packages lokal zu installieren. Das klingt jetzt etwas verwirrend, aber es ist eigentlich recht simpel. Mal angenommen der Webworker möchte sein eigenes Boilerplate erstellen. Das Boilerplate soll als Repository auf Github abgelegt werden, und jedes Mal, wenn er ein Projekt startet, lädt er dieses Boilerpate von Github herunter und alle benötigten Packages werden vor Projektbeginn wie oben beschrieben automatisiert installiert. Dazu benötigt er also eine Datei wie die oben gezeigte. Hier die Beschreibung der einzelnen Properties und ihre Funktion:
Unter name wird der Namen des Packages vergeben.
version zeigt die Versionsnummer an.
Mit authors werden alle Autoren des Packages in einem Array aufgelistet.
description beschreibt das Package, also was macht es und wofür ist es da.
Das Array keywords sorgt für eine bessere Auffindbarkeit durch definierte Suchbegriffe.
Es kann eine Lizenz für den Gebrauch des packages unter license deklariert werden.
Unter homepage wird eine Internetseite zum Package angegeben, wenn vorhanden.
private sorgt dafür, dass das Package in die offizielle Registrierung für Bower aufgenommen wird oder auch nicht.
Mit ignore können Dateien innerhalb des Package-Ordners deklariert werden, die nicht mit geladen werden sollen.
dependencies spielt eine herausragende Rolle, denn hier werden die Packages aufgeführt, die heruntergeladen werden müssen, damit das Projekt bzw. Package funktioniert.
Und devDependencies schließlich beinhaltet die Dateien, die nur für die Entwicklung, nicht die Anwendung bzw. Ausführung des Packages benötigt werden (das können z. B. Dokumentationen oder Logfiles sein).
Will der Developer lediglich die in der Konfigurationsdatei aufgeführten Dependencies lokal installieren, also ohne Registrierung, reicht eine Datei wie die folgende aus:
{
"name" : "Mein Packagename",
"version" : "Meine Packageversion, z. B. 1.0.0",
"main" : "Mein Pfad zur Hauptdatei des Packages",
"ignore" : [
"Datei, die nicht mitgepackt werden soll 01",
"Datei, die nicht mitgepackt werden soll 02..."
],
"dependencies" : {
"Package, das benötigt wird 01" : "Versionsnummer",
"Package, das benötigt wird 02" : "Versionsnummer",
"Package, das benötigt wird 03" : "Versionsnummer",
},
"devDependencies" : {
"Datei, die nur zur Entwicklung des Packages benötigt wird 01" : "Versionsnummer",
"Datei, die nur zur Entwicklung des Packages benötigt wird 02" : "Versionsnummer",
"Datei, die nur zur Entwicklung des Packages benötigt wird 03" : "Versionsnummer"
}
}
bower.json nur zur Installation
Die zweite Konfigurationsdatei im Repo neben der bower.json ist dann die .bowerrc. Diese liegt im selben Verzeichnis wie die bower.json und sorgt dafür, dass die Dependencies in einen unter directory definierten Ordner geladen werden. Diese Datei ist optional – wenn sie nicht vorhanden ist wird einfach wieder ein neuer Ordner namens bower_components erstellt. Auch in dieser Datei wird mit einem JSON-Objekt gearbeitet und das sieht so aus:
{
"directory" : "[Pfad zum Ordner, in dem das Package landen soll]",
"json" : "[Die Konfigurationsdatei, per Default bower.json"
}
.bowerrc
Um die Dateien aufzurufen genügt es, über die Konsole den Pfad zum Repository anzuwählen und den Befehl bower install einzugeben. Bower führt dann automatisch die konfigurierten Aktionen aus.
Ein eigenes Package für Bower registrieren
Die Packages, die über Bower installiert werden können, sollten vorher vom Webworker für diesen Zweck registriert werden. Somit werden sie bei den Bower components veröffentlicht, eine Auflistung von Git-Endpoints. Die Registrierung geschieht in der Datei wie oben bereits beschrieben oder über die Konsole mit folgendem Befehl:
bower register <Package name> <Git-Endpoint>
Git-Endpoint steht dabei für die URL, die auf das Github-Repository des Packages verweist.
Die programmatische API
Auf die programmatische API von Bower soll an dieser Stelle nur mal kurz eingegangen werden. Sie kann sich als recht nützlich erweisen, wenn der Package Manager mit einem Task Runner wie z. B. Grunt verknüpft werden soll. Bower stellt dafür das bower.commands Objekt zur Verfügung, das folgendermaßen aufgebaut werden kann:
var bower = require('bower');
bower.commands
.install(paths, options)
.on('end', function(data){
data && console.log(data);
});
Beispielsnippet für die API
bower.commands kennt vier Events, die ein Callback zulassen, nämlich log, prompt, error und end. Um die Wichtigsten zu nennen, error reagiert auf eine Fehlermeldung während der Installation und end wird nach der Fertigstellung gefeuert.
Fazit
Das war nur ein kurzer Ausflug in die Welt von Bower. Ich nutze den Package Manager seit einiger Zeit in meinen Projekten und möchte ihn nicht mehr missen. In Tateinheit mit Grunt und anderen Tools auf Basis von node.js und npm wird der tägliche Workflow extrem beschleunigt und vereinfacht. Dadurch gewinne ich mehr Zeit für das Wesentliche. Den Code.
Wer als Webworker für Online-Magazine oder sein eigenes Blog schreibt, wird früher oder später auch Code-Beispiele bringen. Der Quelltext ließe sich schlicht mit code und pre auszeichnen. Heutzutage darf sich ein Autor aber durchaus die Mühe machen, seinen Code etwas sinnvoller zu präsentieren – zum Beispiel mit Syntax Highlighting.
Als wir hier auf webkrauts.de die ersten Artikel veröffentlicht haben, sahen die Code-Beispiele im Quellcode noch so aus:
Offensichtlich haben wir damals <pre> nicht genutzt, sondern die Zeilen per eingerückt. Wichtige Stellen wurden per <spanstyle="color: #a00"> eingefärbt (weil ein Autor Inline-Styles benutzen, aber nicht am CSS rumwerkeln durfte). Und natürlich mussten wir ein <div> als <div> oder zumindest <div> schreiben, damit es richtig als Code dargestellt wurde. Das können wir heute belächeln oder den Kopf schütteln – aber hey, es war 2005.
Code-Beispiele auf anderen Websites
Acht Jahre später sieht die Sache schon anders aus. Sowohl Autoren als auch Leser können mehr von Code-Beispielen erwarten. Das beginnt mit einem passenden Syntax Highlighting. Dabei werden bestimmte Elemente eines Codes anders dargestellt – eben die Syntax hervorgehoben. In dem Beispiel oben sind etwa die HTML-Tags fett dargestellt, Werte für die Attribute erscheinen in rot, HTML-Entitäten in ocker. Das ist meist hilfreich, um die einzelnen Elemente einer Sprache schneller zu erfassen. Was noch möglich ist, zeigt ein Blick auf die Code-Beispiele von anderen Websites.
Syntax Highlighting mit JavaScript
Syntax Highlighting auf Smashing Magazine mit Prism
Das Beispiel von Smashing Magazine ohne JavaScript
Zeilennummern
Die Website A Beginner’s Guide to HTML & CSS bietet Einsteiger-Kurse für HTML und CSS. Ein orangener Hinweis oben rechts zeigt deutlich das Thema an. Der Hinweis wird per CSS ausgeblendet, sobald ein Benutzer mit der Maus über dem Code hovert. Zusätzlich gibt es hier eine Zeilennummerierung. Das ist für Code-Beispiele recht hilfreich, weil sich der Autor bei längeren Beispielen einfach im Artikel auf eine Zeile beziehen kann.
Syntax Highlighting auf A Beginner’s Guide to HTML
Im Einsatz ist hier eine aufgehübschte Version von Prettify, einer weiteren JavaScript-Bibliothek. Ohne JavaScript sieht der Code so aus:
Das Beispiel von A Beginner’s Guide to HTML ohne JavaScript
Kleiner Exkurs: Welches HTML-Konstrukt ist sinnvoll, um die Zeilennummern hinzuzufügen?
Am einfachsten wäre es, einfach eine Zahl an den Anfang jeder Zeile zu schreiben. Das hat den Nachteil, dass die Zahlen in jedem Fall bei Copy & Paste mitkopiert werden. Das ist wenig benutzerfreundlich, weil der Nutzer die Zeilennummern per Hand wieder entfernen müsste.
Auf jquery.com wird eine Tabelle um den Code gebaut. Eine Tabellenzelle (td) trägt alle Zeilennummern, die nächste Tabellenzelle den kompletten Code. Per Copy & Paste wird hier nur der Code kopiert. Allerdings würden einem Screenreader auch alle x Zeilennummern hintereinander vorgelesen, das kann nicht sinnvoll sein.
Die meisten Syntax Highlighter bauen eine nummerierte Liste um den Code. Damit lässt sich grundsätzlich arbeiten. Ein Copy & Paste in einen üblichen Texteditor wie Sublime Text kopiert auch hier nur den reinen Text.
Erfahrene Webworker werden sicher einen professionellen Editor bevorzugen. Bei Anfängern muss das nicht unbedingt der Fall sein. Falls jemand auf die Idee käme, sein HTML mit Word oder Open Office zu schreiben, würden bei Copy & Paste jede Mege unerwünschter Zusatzinfos kopiert. Das betrifft nicht nur die Zeilennummern, sondern auch Schriftfarben und andere Auszeichnungen.
Hervorgehobene Stellen
Auf HTML Dog wiederum gibt es zwar keine Zeilennummern, dafür sind wichtige Stellen im Code hervorgehoben.
Syntax Highlighting bei HTML Dog
In diesem Beispiel kommt dazu ein <em> zum Einsatz. Aus HTML5-Sicht wäre <mark> besser geeignet. Mit passendem CSS bleiben die hervorgehobenen Stellen so auch erhalten, wenn JavaScript ausgeschaltet ist:
Syntax Highlighting bei HTML Dog ohne JavaScript
Zu lange Zeilen
Was tun mit zu langen Codezeilen? In einem Editor gibt es keine Probleme mit zu langen Zeilen. Diese werden in der Regel automatisch sinnvoll umbrochen. In einem Artikel auf einer Webseite funktioniert das leider nicht so leicht. Genau genommen gibt es keine einzige gute Lösung. Es kommen einige Spielarten in Frage, die alle ihre Nachteile haben:
Ein overflow: hidden kommt nicht Frage; der komplette Code muss schließlich sichtbar sein.
Auf Smashing Magazine werden zu lange Zeilen per CSS mit word-wrap: break-word; umbrochen. Das sieht zunächst hübscher aus, hat aber den Nachteil, dass wichtige Elemente wie Attribute oder Eigenschaften mitten im Wort getrennt werden könnten.
Hier auf webkrauts.de nutzen wir overflow: auto;, was für einen Scrollbalken sorgt. Wörter werden zwar nicht irgendwo getrennt, dafür kann ein Leser nun ggf. nicht mehr alles auf einen Blick erfassen.
Möglich wäre, zu lange Zeilen künstlich in mehrere aufzuteilen. Aber wo genau endet eine Zeile? Bei einem fixen Layout mit Monospace-Schrift für den Code lässt sich vielleicht eine maximale Buchstabenanzahl pro Zeile festlegen. Aber bei einem responsive Design wird das nicht mehr funktionieren.
Einige Seiten wie zum Beispiel lullabot.com arbeiten mit einem Codeblock, der sich horizontal aufklappt, wenn ein Leser mit der Maus über den Block fährt. Das macht die Seite allerdings recht unruhig, und der Scrollbalken kommt trotzdem zum Einsatz.
Auf lullabot.com klappt die Code-Box bei einem Hover nach rechts aus
Externe Dienste
Eine ganz andere Lösung wäre, die Code-Beispiele direkt auszulagern. Christian Heilmann macht das zum Beispiel in diesem Artikel, bei dem alle Beispiele direkt über jsFiddle eingebunden sind. Sieht hübsch aus und hat den klaren Vorteil, dass der Leser sofort selbst mit dem Code herumspielen könnte. Auf der anderen Seite: Sollte jsFiddle seine Dienste einmal einstellen, wären alle Beispiele weg. Das muss also jeder Autor für sich selbst abwägen. Falls der Dienst erst in ein paar Jahren webgbrechen sollte, ist es vielleicht egal, weil diese alten Artikel dann ohnehin nicht mehr auf dem aktuellen Stand der Technik wären.
Anforderungen und Wunschliste
All die Effekte und Auszeichnungen könnte ein Autor selbst in seinen Quellcode schreiben. Das bietet zwar die größtmögliche Kontrolle, ist aber nicht effektiv. Zum einen macht es viel mehr Arbeit, seine Code-Beispiele sinnvoll umzuwandeln. Zum anderen verändert sich das Web nun einmal. Ein paar Jahre später ist es vielleicht besser, seinen Code etwas anders auszuzeichnen. Und wer arbeitet daraufhin schon all seine alten Beispiele nach?
Es läuft daher auf eine Bibliothek hinaus, die den Quellcode im Hintergrund aufbereitet. Das kann auf zwei Arten passieren. Entweder wird der Code bereits auf dem Server vorbereitet oder per JavaScript im Browser umgewandelt. Soll es nicht noch dynamische Effekte geben, dürfte eine Vorbereitung auf dem Server effektiver sein: Der Webworker spart ein wenig JavaScript, der Code erscheint auch ohne JavaScript hübsch aufbereitet und lässt sich aus dem Cache des CMS bereits komplett ausliefern.
Je nach persönlichen Vorlieben kommen diese Anforderungen in Frage:
Die Bibliothek sollte alle benötigten Sprachen verstehen und highlighten können. Das sind für Webworker erst einmal HTML, CSS und JavaScript. Je nach Themengebiet des Autors kommen Sprachen wie XML, PHP, Ruby, Java, C++ etc. hinzu.
Das Tool sollte von den Machern weiterentwickelt werden. Für ein reines Highlighting reichen auch ältere Bibliotheken von 2008, aber auf Dauer will ein Autor sicherstellen, dass neuere Sprachen und Formate wie etwa SASS, LESS oder JSON auch vernünftig dargestellt werden.
Das Highlighting passiert ordentlich über Klassen und nicht über Inline-Styles.
Zeilen sollten optional nummeriert werden können. Es bietet sich an, den Code als nummerierte Liste darzustellen. Der generierte Code sollte in jedem Fall auch für Screenreader sinnvoll zu lesen sein.
Zeilen sollten per Klasse angesprochen werden können. Sinnvoll ist eine alternierende Klasse, um gerade und ungerade Zeilen farblich zu unterscheiden. Letzteres lässt sich bei modernen Browsern natürlich auch über den Pseudo-Selektor :nth-child() regeln.
Zusätzlich wäre vielleicht eine Syntax wünschenswert, mit der sich bestimmte Teile zusätzlich markieren lassen. Es müsste dann eine Syntax geben, die wahlweise per <mark> Code nochmals optisch hervorhebt oder aber <mark> als Text ausgibt, weil das HTML-Element selbst im Code-Beispiel vorkommt.
Aber zum einen ist diese Option vielleicht etwas viel verlangt, zum anderen mögen Syntax Highlighting plus <mark> zusammen optisch zu unruhig wirken.
Nett wäre weiterhin die Option, eine Überschrift oder Unterzeile angeben zu können. Etwa »Listing 4: Das komplette Beispiel«. Das klappt aber auch mit einem entsprechend gestalteten Absatz vor oder nach dem Codeblock.
Und vorzugsweise generiert die Bibliothek validen Quellcode (siehe unten).
Mögliche Highlighter
Welcher Syntax Highlighter kommt nun in Frage? Das hängt von den eigenen Vorlieben ab: JS- oder PHP-Lösung? Unterstützte Sprachen? Vorhandene Themes? Alle Varianten sollte ein Webworker fix selbst einbauen können. In Kombination mit einem Content-Management-System macht man es sich meistens einfacher und nutzt die Bibliothek, die bereits als Modul/Plugin für das CMS vorhanden ist.
Der Filter unterstützt stolze 112 Sprachen und Formate. Darunter natürlich HTML, CSS, JavaScript und PHP. Aber auch LaTeX, Perl, Python, Smarty, Ruby, Ruby on Rails, robots.txt und XML. Er bietet Zeilennummern an. Darüber hinaus lassen sich eingebaute Keywords direkt verlinken, um weitere Informationen zu erhalten. So würde etwa <span> auf december.com verlinken. Diese Seite ist in der aktuellen Form natürlich wenig hilfreich, aber die Idee ist gut.
Da der GeShi-Filter aktuell auf webkrauts.de über ein Drupal-Modul im Einsatz ist, zwei Tipps dazu:
In der Grundeinstellung setzt GeShi einen <pre>-Wrapper um den Quellcode. Mit Zeilennummerierung erzeugt das ein <ol> innerhalb eines <pre>. Das ist laut Validator aber nicht erlaubt. In der Konfiguration lässt sich alternativ auch ein <div> als Wrapper oder kein Wrapper-Element einstellen – beide Optionen liefern validen Code.
Damit der Filter zum Einsatz kommt, packt der Autor seinen Quellcode in einen Container. Dieser kann die Syntax <foo> ... </foo>, [foo] ... [/foo] oder [foo]] ... [[/foo]] haben. Statt »foo« wird die Sprache eingesetzt, etwa html, css, javascript oder php.
Nutzt vorzugsweise nicht die Schreibweise <foo> ... </foo>. Das führt zu Problemen, wenn ihr mal ein <html> im Quellcode benutzen wollt, denn das feuert ja den Filter neu.
Der besagte Highlighter von Lea Verou, der unter anderem beim Smashing Magazin, A List Apart, WebPlatform.org und dem Mozilla Developer Network eingesetzt wird. Diese Namen reichen den meisten schon, um direkt diese Bibliothek zu wählen. Die Bibliothek kennt zunächst 21 Sprachen (darunter Markup, CoffeScript, SASS und SQL). Dabei werden auch ineinander verschachtelte Sprachen richtig ausgezeichnet (CSS in HTML, JavaScript in HTML). Wer will, kann selbst weitere Sprachen hinzufügen. Mit einem Plugin werden auch automatische Zeilennummer möglich. Unterstützt werden IE9+, Firefox, Chrome, Safari, Opera, sowie die meisten mobilen Browser.
Auch highlight.js hat einiges zu bieten. Es unterstützt 67 Sprachen – darunter auch JSON, SQL, XML, ActionScript, SCSS, Haml, Handlebars, Smalltalk. Dazu kommen stolze 32 Themes. Das Tool kann die Sprache automatisch ermitteln und highlighted auch verschiedene Sprachen im Code. Nach der Demo und den kurzen Doku zu urteilen, gibt es hier aber keine Zeilennummern. Außerdem fehlt eine Info zu den unterstützen Browsern.
Im Netz sind viele weitere JS-Highlighter zu finden. Zum Beispiel SyntaxHighlighter, Prettify, SHJS, Lighter oder Rainbow. Die meisten sind im Vergleich zu den beiden genannten nicht besonders gut dokumentiert, bieten deutlich weniger Funktionen und/oder wurden seit Jahren nicht aktualisiert.
Wer also auf der Suche nach einem Highlighter ist, dürfte mit einer der drei Bibliotheken – GeShi, Prism oder highlight.js – gut bedient sein.
Fazit
Vielleicht findet der ein oder andere hier die Inspiration, seine eigenen Code-Beispiele etwas aufzupeppen. Schließlich ist es nicht so schwer, eine der vorhandenen Bibliotheken einzubinden. Auch hier auf webkrauts.de können wir noch dieses oder jenes verbessern: Schriftart und -farben des Codes sehen auf anderen Seiten deutlich ansehnlicher aus. Und das Ocker ist auch nicht wirklich gut lesbar (schon gar nicht im Sinne der Barrierefreiheit). Da werden wir beizeiten nachbessern müssen.
Um Interaktionen über einen Touchscreen zu berücksichtigen, müssen Entwickler oft separaten Code für Maus- und Touch-Events schreiben. Im Internet Explorer 10 wurde mit Pointer-Events ein komplett umgedachtes Modell eingeführt: Damit ist es möglich, Interaktionen über Maus, Stylus oder Touchscreen in einem Event zusammenzufassen.
Im letzjährigen Adventskalender gab es eine schnelle Einführung zu Touch-Events. Wie schon damals erwähnt, werden Touch-Events in fast allen modernen Browsern unterstützt… mit Ausnahme von Internet Explorer. Obwohl Microsoft lange Zeit auf Touch-fähigen mobilen und »Desktop«-Geräten präsent war, gab es anfangs keine Möglichkeit, Touchscreen-spezifisches JavaScript im Internet Explorer einzusetzen. Entwickler waren darauf angewiesen, auf (simulierte) Maus-Events zu reagieren.
Anstatt anderen Browsern nachzuziehen und auch Touch-Events (mit den damit verbundenen Problemen, die schon im Adventskalender-Artikel zum Thema kurz zusammengefasst wurden) einzusetzen, wurde im Internet Explorer 10 (in Windows Phone 8 und Windows 8/RT) mit Pointer-Events ein komplett umdachtes Modell eingeführt.
Vorteile von Pointer-Events im Vergleich zu Touch-Events
Touch-Events sind speziell auf Touchscreens ausgesetzt – Entwicklern müssen deshalb in vielen Fällen separaten Code für Maus- und Touch-Interaktionen schreiben.
/* Pseudo-Code: zur Bearbeitung von Maus- und Finger-Bewegungen
benötigt im Touch-Event Modell separate Funktionen */
Darüber hinaus müssen sich Entwickler noch mit einer Eigenheit von Touch-Events auseinandersetzen: die Koordinaten der verschiedenen Touch-Punkte sind bei Touch-Events nicht direkt im Event, sondern in separaten TouchList-Arrays untergebracht (siehe dazu die W3C Spezifikation zu TouchEvent und Touch). Im Endeffekt benötigen sie also separaten Code, um Maus- und Finger-Bewegungen in JavaScript zu bearbeiten.
/* Pseudo-Code: Koordinaten in Maus- und Touch-Events */
foo.addEventListener('mousemove', function(e){
...
/* Bei Maus-Events sind die Koordinaten
direkt im Event-Objekt vorhanden */
posX = e.clientX;
posY = e.clientY;
...
}, false);
foo.addEventListener('touchmove', function(e){
...
/* Bei Touch-Events muss man mit
TouchList-Arrays arbeiten, selbst
wenn man nur einen einzigen Touch-Punkt
bearbeiten moechte */
posX = e.targetTouches[0].clientX;
posY = e.targetTouches[0].clientY;
...
}, false);
Pointer-Events bieten hingegen einen Abstraktionslayer, der alle möglichen Inputs (Maus, Touch, Stylus) in ein einheitliches Event-Modell unterbringt. Die neuen Events sind den traditionellen Maus-Events sehr ähnlich: pointerenter, pointerover, pointerdown, pointermove, pointerup, pointerout, pointerleave. Darüber hinaus gibt es im Pointer-Event-Modell noch einige spezielle Events – pointercancel, getpointercapture, lostpointercapture– auf die in dieser Einführung aber nicht weiter eingegangen wird.
Somit ermöglichen Pointer-Events, den Code relativ zu vereinfachen, indem Entwickler nur noch auf eine generelle Art von Events reagieren müssen:
/* Pseudo-Code: zur Bearbeitung von Maus-, Finger- und Stylus-Bewegungen
brauchen im Pointer-Event Modell nur eine einzige Funktion */
Im Gegensatz zu Touch-Events, die ein komplett eigenes Event-Objekt haben, sind Pointer-Events an sich nur eine Erweiterung von klassischen Maus-Events. Jegliche Berührungspunkte (Finger oder Stylus auf einem Touchscreen) und Maus-Interaktionen generieren ein Event-Objekt, das alle normalen Maus-Events Properties beinhaltet (inklusive der individuellen Koordinaten-Paare). Dazu kommen weitere Properties, die den Events mehr Informationen zum Input mitliefern (siehe dazu die W3C Spezifikation zur PointerEvent interface). Somit ist es einfach, älteren Code – der speziell auf Maus-Events abgerichtet war – unmodifiziert auch für Pointer-Interaktionen einzusetzen. In den meisten Fällen reicht es aus, anstatt auf Maus-spezifische Ereignisse wie mousemove einfach den gleichen JavaScript bei pointermove auszuführen.
/* Pseudo-Code: zur Bearbeitung von Maus-, Finger- und Stylus-Bewegungen
brauchen Entwickler im Pointer-Event-Modell nur eine einzige Funktion, und jeder
Pointer-Event enthält direkt die Koordinaten, genau wie bei Maus-Events */
foo.addEventListener('pointermove', function(e){
/* "e" beinhaltet unter anderem die folgenden Properties:
Falls eine Applikation trotzdem speziell auf verschiedene Inputs anders reagieren soll (um zum Beispiel ein Hover-Menu nur für Maus-User anzuzeigen), erlauben Pointer-Events, die Quelle/Art des Events mittels der pointerType Property abzufragen.
/* Pseudo-Code: verschiedenen Code je nach pointerType ausführen */
switch(e.pointerType){
case"mouse":
...
break;
case"pen":
...
break;
case"touch":
...
break;
}
Somit erlauben Pointer-Events einen »best of both worlds«-Ansatz: meistens ist es eigentlich egal, wie ein User mit einer Web-Applikation interagiert – ob ein Link oder Button per Maus oder Touch aktiviert wurde. Da in allen Fällen die gleichen Pointer-Events abgefeuert werden, ist es somit möglich, »Input-agnostischen« Code zu schreiben. Trotzdem können die verschiedene Input-Arten im Code differenziert werden.
»Feature detection« für Pointer-Events
Um festzustellen, ob ein Browser Pointer-Events unterstützt, reicht ein einfacher Feature-Detect:
if(window.PointerEvent){
/* Browser mit Pointer-Events */
}
Man beachte hier, dass Pointer-Events nicht nur für Touchscreens benutzt werden – selbst auf nicht-touch-fähigen Geräten können Pointer-Events benutzt werden, um auf traditionelle Maus/Trackpad-Inputs zu reagieren.
Pointer-Events definieren auch eine separate navigator.maxTouchPoints Property, die die (Hardware-bedingte) maximale Anzahl an Touch-spezifischen Berührungspunkte angibt. Um nun zu testen, ob der Browser auf einem Gerät mit Touch läuft, können Entwickler einen separaten Feature-Detect benutzen:
if(navigator.maxTouchPoints> 0){
/* Browser auf einem Touch-fähigen Gerät */
}
Grundlagen zur Bearbeitung von Pointer-Events
Wie schon bei der Abhandlung zu Touch-Events besprochen, sind Browser von Haus aus darauf ausgerichtet, existierende Webseiten so gut wie möglich auf Handys und Tablets darzustellen und benutzbar zu machen. Und da die meisten Seiten im Web immer noch auf Maus-Interaktionen ausgerichtet sind, werden selbst in Internet Explorer 10+ auch für Touchscreen-Interaktion traditionelle Maus-Events simuliert.
Man beachte, dass diese Events in dieser Reihenfolge praktisch ohne Zwischenpausen abgesandt werden.
Wenn eine Webseite auf spezifische Events wie click oder mouseover reagiert, wird diese Seite in den meisten Fällen ohne jegliche Veränderung auch in IE10+ auf Touch-Geräten benutzbar sein. Es gibt aber, wie auch bei Touch-Event-fähigen Browsern, einige wohlbekannte Einschränkungen, wenn sich Entwickler nur auf Maus-Events verlassen – unter anderem, eine spürbare 300ms-Verzögerung bei Touch-Interaktionen, bevor der click Event abgesandt wird, und die Tatsache, dass Fingerbewegungen auf einem Touchscreen nicht – wie man es von einer normalen Maus gewohnt ist – mousemove Events generiert.
Pointer-Events und simulierte Maus-Events
Die Event-Reihenfolge im Touch-Events-Modell sieht folgendermaßen aus:
Zuerst werden die Touch-spezifischen Events abgesandt. Dann, nach dem klassichen 300ms Delay, werden die simulierten Maus-Events und zuletzt der click abgefeuert.
Im Pointer-Events-Modell, hingegen, werden die Pointer- und Maus-Events folgendermaßen abgesandt:
Im IE10 (immer noch der Standard-Browser auf Windows Phone 8) sind Pointer-Events mit einem Vendor-Prefix versehen. Somit sehen die verschiedenen Events in dieser Version so aus: MSPointerOver, MSPointerEnter, MSPointerDown, MSPointerMove, MSPointerUP, MSPointerOut, MSPointerLeave. In IE11 sind die Events gemäß der W3C Spezifikation ohne Prefix implementiert.
Verkürzte Reaktionszeit bei click Events
Wie schon letztes Jahr gesehen, gibt es bei Touchscreens in der Regel eine Verzögerung von ungefähr 300ms zwischen dem Moment, in dem der Finger bei einem »Tap« den Touchscreen verlässt, und dem click Event. Um bei Touch-Events diese Verzögerung zu umgehen, müssen sich Entwickler traditionell mit extra Code auseinandersetzen, der sowohl auf touchend (der direkt vor der Verzögerung ausgeführt wird) als auch auf click reagiert, und mittels preventDefault() verhindern, dass die gleiche Funktion doppelt abläuft – einmal für den Touch-Event, und danach für die simulierten Maus-Events.
Zwar könnte man hier einen ähnlichen Ansatz nehmen und auf pointerup und click Events hören. Einziger Haken: Bei Pointer-Events hat preventDefault weder auf die simulierten Maus-Events (die, wie gesehen, »inline« zusammen mit den verschiedenen Pointer-Events abgesandt werden), noch auf den click, einen Effekt.
Pointer-Events haben aber hier eine viel einfachere Alternative. Die Pointer-Events Spezifikation definiert eine neue CSS Property touch-action, mit der es möglich ist, dem Browser explizit mitzuteilen, welche Touchscreen-Interaktionen (und deren »Default« Bearbeitung vom Browser) zugelassen sind.
touch-action: auto | none | pan-x | pan-y
auto: der Browser kümmert sich um alle Touch-Gesten, inklusive »double-tap to zoom« (und damit die 300ms Verzögerung).
none: alle Standard-Touch-Gesten sind unterdrückt.
pan-x und pan-y: überlässt dem Browser auschließlich horizontales oder vertikales Scrolling.
Wie auch mit preventDefault ist hier Vorsicht geboten: touch-action:none unterdrückt nicht nur unerwünschtes Verhalten wie die 300ms Verzögerung, sonder auch andere Interaktionen wie Zooming und Scrolling. Aus diesem Grund sollte diese CSS Property wirklich nur gezielt auf die nötigen Elemente (wie zum Beispiel Links und Buttons), und nicht auf die gesamte Webseite, angewandt werden
Anstatt komplexe JavaScript Routinen einzusetzen, können die 300ms recht elegant mittels einer einzige extra Zeile im CSS unterdrückt werden.
Ein weiteres Problem, das schon im letztjährigen Artikel besprochen wurde, ist die Tatsache, dass Finger-Bewegungen auf einem Touchscreen nicht direkt mittels mousemove verfolgt werden können – sobald sich der Finger mehr als nur ein paar Pixel über den Touchscreen bewegt, wird dies als eine Scroll-Geste interpretiert, und die simulierten Maus-Events werden nicht abgefeuert.
Um Finger-Bewegungen per JavaScript zu verfolgen, müssen Entwickler deshalb im Touch-Event Modell direkt auf touchmove Events reagieren, und mittels preventDefault das Scrollen im Browser unterdrücken.
Das gleiche Problem mit mousemove ist auch in Browsern mit Pointer-Events vorhanden. Als Beispiel dient hier wieder eine Canvas-basierte Spielerei:
Dieses Beispiel funktioniert einwandfrei mit der Maus. Wenn man aber auf einem Touchscreen den Finger über den Canvas bewegt, wird die Bewegung nur für ein paar Pixel verfolgt … danach interpretiert der Browser die Bewegung als Scrolling.
Als ersten Schritt sollten Entwickler echte Pointer-Events, und nicht die simulierten Maus-Events, einsetzen. Anstatt auf mousemove werden die Event-Listener also auf pointermove gesetzt.
Die nächsten Beispiele funktionieren nur in Browsern mit Pointer-Events-Unterstützung – zur Zeit also nur Internet Explorer 10+
Der Effekt ist leider immer noch der gleiche: selbst bei pointermove wird eine Finger-Bewegung als Scroll vom Browser abgefangen. Wie auch mit der 300ms-Verzögerung können Entwickler aber bei Pointer-Events direkt im CSS angeben, ob sich der Browser wie gewohnt um das Scrolling kümmern soll, oder ob Berührungen direkt per Scripting bearbeitet werden sollen. Somit reicht es aus, wieder eine einzige CSS-Zeile zum Beispiel hinzuzufügen:
Dieses Beispiel funktioniert nun schon recht gut. Bewegungen werden sowohl mit dem Finger als auch mit einer Maus registriert, und von dem gleichen Code bearbeitet. Eine Tücke hat es aber noch: das Beispiel ist von Grund auf nur auf ein einziges Koordinaten-Paar ausgerichtet – wenn mehr als ein Finger auf dem Canvas ist, wird immer nur der Berührungs-Punkt, der sich zuletzt bewegt hat, von dem Script wahrgenommen.
Um genauer zu sein, kommt das Problem bei dem vorherigen Beispiel nicht nur mit mehreren Fingern auf dem Touchscreen vor – die gleiche Problematik tritt auf, wenn mehr als ein Pointer (sei es ein Finger, Stylus oder eine Maus) gleichzeitig benutzt werden. Der Einfachheit halber geht der Beispiel-Code davon aus, dass ein User diese verschiedenen Inputs nicht gleichzeitig verwenden wird.
Um nur den »ersten« Finger auf dem Touchscreen zu verfolgen, muss der Code leicht erweitert werden, um nur auf den »primären« Pointer zu reagieren.
/* Pseudo-Code: Koordinaten nur für den primären Pointer erfassen */
Im Gegensatz zu traditionellen Maus- und Touch-Events erlauben Pointer-Events, Web-Applikationen auf elegante Weise auf verschiedene Input-Methoden auszulegen, ohne spezielle »Weichen« (für Maus, Touch, Stylus, usw.) in den Code packen zu müssen.
Momentan sind diese Events leider nur in Internet Explorer 10+ vorhanden – aber Unterstützung in anderen Browsern wird voraussichtlich bald kommen (siehe die aktiven Bugs für Chromium/Blink und Firefox– obwohl es momentan noch unsicher ist, ob Webkit auch nachziehen wird). Um trotzdem schon heute das vereinfachte Pointer-Event-Modell einzusetzen, gibt es schon recht stabile Polyfills wie HandJS und Polymer's PointerEvents.
Was heutzutage alles in den Head muss – und was nicht
René Descartes sagte einmal »Denn es ist nicht genug einen guten Kopf zu haben; die Hauptsache ist ihn richtig anzuwenden«. Auch wenn Descartes nicht viel mit dem Internet anfangen konnte, gilt diese Weisheit auch für Websites. Was gehört also wirklich in einen guten Kopf einer Website?
Die Ausgangslage bei typischen Meta-Tag-Angaben sah vor zehn Jahren noch recht überschaubar aus:
<head>
<title>Over<head> | Webkrauts</title>
<metaname="keywords"content="meta-tags, meta-attribute, head, html, suchmaschinen, seo, favicon" />
<metaname="description"content="Welche Meta-Tags gehören in den Head-Bereich einer Website?" />
Fast Forward nach 2013: Mittlerweile ist das »keywords«-Meta-Tag obsolet, es wird von keiner großen Suchmaschine mehr unterstützt, da zur Verschlagwortung der eigentliche Inhalt der Seite herangezogen wird. Bei der Description hat sich hingegen nicht viel geändert: Sie wird weiterhin von den Suchmaschinen als Beschreibung des Links genutzt. Einzig in der maximalen Länge unterscheiden sich die verschiedenen Anbieter. Hier wird eine Länge von 160 bis 200 Zeichen empfohlen.
Das Favicon
Früher genügte eine einzige Datei im ICO-Format von Windows, die ein 16×16px großes Icon enthielt, das der Browser dann bei Bookmarks zusätzlich anzeigte. Alle waren glücklich.
Heute empfiehlt es sich, ein paar Größen mehr zu unterstützen: Für die verschiedenen Systeme, Auflösungen und Funktionen werden die Seitenlängen 16, 24, 32 und 64 Pixel benötigt, die als weitere Bilder innerhalb der Favicon-Datei selbst gespeichert werden (etwa für die unten beschriebenen »Pinned Sites«).
Ein freier und guter Favicon-Generator dafür ist der X-Icon Editor. Dort kann man PNGs hochladen und sich eine ICO-Datei mit mehreren Auflösungen generieren lassen. Moderne Browser unterstützen neben dem ICO-Format auch PNG oder GIF, allerdings macht uns hier der Internet Explorer einen Strich durch die Rechnung, der diese Formate erst ab Version 11 unterstützt. Daher empfiehlt es sich, beim ICO-Format zu bleiben.
Wird im Head-Bereich der Seite kein Metatag für die favicon.ico-Datei angegeben, wird vom Browser nach einer Datei dieses Namens im Root-Verzeichnis der Website gesucht. Diese Angabe wird also nur benötigt, wenn das Favicon an einem anderen Ort liegt.
Touch-Icons für iOS & Android
Mit dem iPhone wurde zusätzlich zum Favicon ein neues Bild-Element als Meta-Angabe hinzugefügt: Das »apple-touch-icon« mit einer Bildgröße von 57×57px. Es wird angezeigt, sobald der Benutzer den Link zu einer Website auf seinem iPhone-Homescreen speichert. Trotz des Namens haben kurz darauf Android-Handys dieses Verhalten übernommen.
Bei diesem Icon wurde bis einschließlich iOS6 automatisch ein typischer Glanzeffekt hinzugefügt, wie er auch bei den Apple-eigenen Applikationen vorgesehen war. Wenn dies bewusst nicht gewünscht ist, muss die Icon-Datei stattdessen »apple-touch-icon-precomposed.png« benannt werden.
Im Laufe der Zeit ist durch Tablet- und Retina-Versionen der Geräte die Anzahl zunächst auf 4 quadratische Größen gewachsen: 57px, 72px, 114px und 144px, mit der Einführung von iOS7 sind bei Apple auch noch die Größen 60px, 76px, 120px und 152px hinzugekommen. Mit der Umstellung auf »Flat Design« allerorten, sollte für ein einheitliches Erscheinungsbild auf unterschiedlichen Geräten die precomposed-Variante verwendet werden. Ab iOS7 wird auch der Glanzeffekt immer weggelassen.
Um sämtlichen Varianten Rechnung zu tragen, muss der folgende Block in den Header einfügt werden:
Sind keine Touch-Icons in der Seite enthalten, sucht zumindest iOS im Root der Website nach den Dateien in der Reihenfolge apple-touch-icon.png und apple-touch-icon-precomposed.png, ignoriert aber weitere Dateinamen mit Größenangaben. Der empfehlenswerte Artikel von Mathias Bynens geht dabei ausführlich auf die Entstehung und Entwicklung der Touch-Icons ein.
Viewport
Um eine Website auch fit für die mobilen Geräte zu machen, benötigen diese den Viewport-Meta-Tag. Diese Anweisung beschreibt, wie ein Gerät mit geringerer Bildschirmgröße – meist ein Handy – mit der Seite umgehen soll. Um eine Seite mit einer Breite von 1200px auf ein 480px breites Handy-Display zu bringen, gibt es verschiedene Ansätze: Man zoomt auf eine bestimmte Auflösung, lässt den User selber skalieren oder gibt einen bestimmten Zoom-Faktor an.
Folgendes Beispiel gehört zu einer Website, die bereits »responsive« ist, und somit mit allen Auflösungen funktioniert.
Eine genaue Beschreibung des Viewport-Meta-Tags und den Hintergründen findet sich im Webkrauts-Archiv: Ein Blick durch den Viewport.
Funktionen für Windows 7 und 8 im Internet Explorer
Microsoft hat seinen Betriebssystemen ab Version 7 in Verbindung mit dem Internet Explorer als Standardbrowser ein paar weitere Funktionen spendiert:
Pinned Sites
Webseiten können nicht nur in den Bookmarks gespeichert, sondern auch in der Windows-Taskbar abgelegt werden. Dazu wird ein 32×32px großes Favicon benötigt, das mit einem Icon-Editor schon im favicon.ico gespeichert wurde. Um etwas mehr Einfluss auf den Link zu haben, hat Microsoft noch folgende Meta-Tags definiert:
<metaname="application-name"content="Der Name der Website">
<metaname="msapplication-tooltip"content="Ein kleiner Erklärungstext wie er beim Hover erscheinen soll.">
Jump Lists
In Windows 7 waren auch sogenannte »Jump Lists« möglich. Diese wurden in das Rechts-Klick-Menü eingefügt, wenn der Nutzer auf die Seite in der Taskbar klickt. Für jeden Eintrag in das Menü kann ein Meta-Tag definiert werden, der wie folgt aussieht:
Für die Icons kann z.B. der oben schon erwähnte X-Icon-Editor verwendet werden.
Tiles-Infos
Unter Windows 8 kann eine Website auch im Startmenü als Kachel hinterlegt werden. Dazu werden die Farbe, die Kachel-Grafik (144×144px, einfarbig, transparent) und folgende Meta-Tags benötigt:
Hier empfiehlt es sich, Kontrastfarben zu setzen. Um das Aussehen der Kacheln vorab zu testen, stellt Microsoft ein Tool zur Verfügung: Build my pinned site.
Optional kann auch ein RSS-Feed eingebunden werden, dann wird die Kachel regelmäßig mit neuem Inhalt befüllt.
In älteren Versionen des Internet Explorers kann es noch bisweilen Darstellungsprobleme auf Webseiten geben, wenn der sogenannte »Kompatibilitätsmodus« aktiviert ist. Das hat zur Folge, dass versucht wird, das Verhalten älterer Browser (z.B. des IE7 oder IE6) zu imitieren. Das führt bei standardkonformem HTML meist zu sehr unschönen Ergebnissen. Mit dieser Metatag-Angabe kann der IE dazu gezwungen werden, stets die aktuellste Version seiner Rendering-Engine einzusetzen:
Detaillierte Informationen zu weiteren Einstellungsmöglichkeiten gibt es direkt bei Microsofts Developer Network. Durch die deutlich verbesserte Unterstützung in aktuellen Versionen des Internet Explorers, verliert dieser Meta-Tag allerdings zusehend an Bedeutung.
SEO
Um die Qualität der Suchergebnisse zu verbessern, haben einige Suchmaschinen-Anbieter – allen voran Google – beschlossen, sogenannten »Duplicate Content« abzuwerten. Dieser entsteht zum Beispiel, wenn eine Webseite sowohl unter domainname.de als auch www.domainname.de erreichbar ist (Suchmaschinen werten dies als zwei unterschiedliche Adressen). Duplicate Content liegt ebenso vor, wenn der gleiche oder fast der gleiche Inhalt etwa in mehreren Kategorien einer Website (und damit unter mehreren URLs) zu finden ist.
In diesen Fällen wird den Suchmaschinen mitgeteilt, wo der Original-Text liegt, der für die eigentliche Indizierung verwendet werden soll, und ihr umgeht eine Abstrafung durch den Suchmaschinen-Betreiber:
Die großen Content-Management- bzw. Blog-Systeme wie WordPress, Drupal oder Joomla setzen die Tags meist automatisch – oder es gibt Module dafür. Um sicher zu gehen sollten aber unbedingt die Einstellungen und der ausgegebene Quelltext überprüft werden. Auf statischen Seiten hingegen kann auf diesen Tag verzichtet werden, wenn dort Inhalte nicht über mehrere URLs aufrufbar sind.
DNS-Prefetching
Bevor eine Ressource auf einer Website (z.B. JavaScript, CSS, Bilder) geladen werden kann, muss der Browser erst den DNS-Eintrag auflösen. Das dauert in der Regel nur wenige Millisekunden. Lädt der Browser nun viele Inhalte von anderen Domains, etwa über ein Content-Delivery-Network oder verwendete Werbung oder Zählpixel, kann es besonders bei mobiler Internetnutzung mit hohen Latenzen zu Verzögerungen kommen. Ihr könnt allerdings den Browser anweisen, die DNS-Informationen vorab zu laden, wenn sich ein freies Zeitfenster dafür ergibt:
<linkrel="dns-prefetch"href="//www.example.com">
Wird etwa der jQuery-CDN und Google Analytics im Projekt verwendet, sähe ein passender Eintrag so aus:
Generell sollte das Zeichen-Encoding einer Website bereits dem Browser vom Web-Server im HTTP-Header mitgeteilt werden, zusätzlich kann diese Einstellung als Meta-Tag mitgegeben werden. Für HTML5 wird dabei UTF-8 als Standard angenommen, so dass auf diese Auszeichnung auch verzichtet werden kann:
<metacharset="utf-8">
Nach dieser grundlegenden Übersicht der aktuell geläufigsten Meta-Angaben geht es im morgigen zweiten Teil um weitere Möglichkeiten speziell für Social Media und Tracking-Dienste.
Tagtäglich posten Millionen Nutzer etliche Links in den sozialen Netzen. Es heißt, allein auf Facebook werden alle zwanzig Minuten eine Million Links geteilt. Grund genug, die eigene Website für Social Media herzurichten. Mit Hilfe der passenden Meta-Tags.
Ging es im ersten Teil um die allgemeinen Infos, die in den head einer Seite sollten, beschäftigt sich der zweite Teil mit den Infos, die verschiedene soziale Netzwerke für die Verlinkung der Seite benötigen. Dort hat jeder Anbieter seine eigenen Vorstellungen und Ideen.
Open Graph
Der Branchenprimus Facebook hat vor einigen Jahren den »Open Graph« eingeführt, um Webseiten besser maschinenlesbar zu gestalten. Dadurch wird die Vorschau der verlinkten Seiten auf Facebook mit Inhalten und Infos angereichert, wie z.B. einer Beschreibung oder aussagekräftiger Bilder. Mittlerweile ist das Protokoll der Quasi-Standard und damit weit verbreitet – nicht nur bei Facebook.
Damit diese Daten von sozialen Netzwerken auch gelesen werden können, müssen ein paar Meta-Tags im head gesetzt werden:
<meta property="og:title"content="More Over<head>: Social Media">
<meta property="og:description"content="Welche Meta-Tags können im <head> für Soziale Netzwerke verwendet werden?">
Bei »og:title« handelt es sich um die Überschrift der Seite, »og:description« beinhaltet eine kurze Zusammenfassung. Die im ersten Teil beschriebene Canonical-URL sollte im »og:url« Meta-Tag ebenfalls enthalten sein. »og:type« beschreibt hingegen die Art des verlinkten Inhalts, der entweder als Website (»website«), Buch (»book«), Produkt (»product«) oder Artikel (»article«) klassifiziert ist.
Das passende Bild zur Seite (etwa ein Screenshot, Teaser oder das eigene Logo) wird mit »og:image« hinzugefügt. Facebook gibt hier eine Mindestgröße von 600×315 Pixel vor. Das Seitenverhältnis sollte idealerweise 1.91:1 sein, da Facebook Bilder entsprechend zuschneidet. Bei anderen sozialen Netzwerken (etwa Twitter) können diese Angaben aber auch abweichen, wie im Folgenden noch zu sehen ist. Daher lässt sich mit diesem Tag auch mehr als ein Bild definieren, etwa mit verschiedenen Größen oder Motiven:
Die Größe eines Bildes wird immer jeweils nach dem Bild angegeben. Dazu nimmt man die spezifischere Auszeichnung »og:image:width«, diese bezieht sich dann auf die letzte allgemeinere Information »og:image«. Der Besucher der Seite kann sich dann das Bild in seinem sozialen Netzwerk beim Verlinken aussuchen. Ideal ist es, seitenspezifische Bilder anzugeben und nicht nur immer die gleichen allgemeinen Bilder.
Twitter Cards
Auch Twitter bietet seit Anfang 2013 die Möglichkeit, einen Link »anzureichern«. Um die sogenannten »Twitter Cards« nutzen zu können, muss die eigene Seite bei Twitter allerdings noch freigeschaltet werden. Der genaue Ablauf ist in der Twitter Developers Dokumentation beschrieben. Die Syntax einer Twitter Card sieht dabei folgendermaßen aus:
<metaname="twitter:card"content="summary">
<metaname="twitter:site"content="@andiweiss">
<metaname="twitter:creator"content="@andiweiss">
<metaname="twitter:title"content="">
<metaname="twitter:description"content="">
<metaname="twitter:image"content="beispiel.jpg">
Der von Twitter gewählte Aufbau sieht in einigen Punkten der »Open Graph«-Struktur sehr ähnlich. Kein Wunder, sie benötigen ja größtenteils die gleichen Informationen. Nutzt ihr die Meta-Angaben für beide Dienste, könnt ihr euch doppelte Schreibarbeit sparen. Fehlen benötigte Angaben in den Twitter-Auszeichnungen, wird automatisch nach entsprechenden »Open Graph«-Daten auf der Seite gesucht:
Twitter Card
Open Graph
Anmerkungen
twitter:url
og:url
Canonical-URL
twitter:description
og:description
max. 200 Zeichen
twitter:title
og:title
max. 70 Zeichen
twitter:image
og:image
je nach Card-Typ
Dadurch werden nur noch ein paar zusätzliche Informationen benötigt, die noch nicht im »Open Graph« angegeben wurden:
<metaname="twitter:creator"content="@andiweiss">
<metaname="twitter:site"content="@webkrauts">
<metaname="twitter:card"content="summary">
»twitter:creator« ist der Twitter-Account des Artikel-Autoren, »twitter:site« ist der Account des Inhabers der Seite. Mit »twitter:card« kann zwischen verschiedenen Darstellungen gewählt werden. Am interessantesten sind hier »summary« und »summary_large_image« zu nennen. Sie beinhalten den Titel, die Beschreibung, den Autor sowie ein Bild der verlinkten Seite und sind für Artikel-Zusammenfassungen gedacht.
Die anderen Möglichkeiten sind die Photo-Card, Gallery-Card, App-Card, Player-Card und die Product-Card.
Twitter bietet in seinem Developer-Bereich auch einen Validator und einen Baukasten für die benötigten Meta-Tags an.
Google+
Google und damit auch Google+ setzen hauptsächlich auf das schema.org-System, um eine Webseite maschinenlesbar zu machen. Die Anreicherung mit Metadaten findet hier allerdings im Body statt und fällt damit aus dem Rahmen dieses Artikels. Aber auch in diesem Fall kommen wieder Meta-Daten mit ins Spiel: Wenn keine schema.org-Deklarationen vorhanden sind, greift Google auch hier auf vorhandene »Open Graph«-Angaben zurück.
Pinterest
Ein anderes Soziales Netzwerk ist Pinterest. Der Reiz dabei liegt vor allem im Verlinken von Bildern auf Webseiten, die hier sehr prominent präsentiert und auch als Kopie auf der Servern von Pinterest abgelegt werden. Wer diesbezüglich Bedenken hat oder es aus Urheberrechtsgründen verhindern möchte, kann das Anpinnen seiner Bilder mit einem einfach Meta-Tag unterdrücken:
<metaname="pinterest"content="nopin" description="Leider erlaubt der Seitenbesitzer kein Pinnen seiner Inhalte.">
Analytics
Ein weiteres Themengebiet sind die Analyse-Tools. Neben Google Analytics bieten auch Facebook und Pinterest die Möglichkeit, die Aufrufe der eigenen Website zu messen, wenn ihr euch über einen Meta-Tag als Besitzer der Seite verifiziert habt.
Facebook Insights
Um Informationen zu Aktivitäten rund um die eigene Seite bei Facebook zu erhalten, könnt ihr euch in Facebook Insights umschauen. Die eigene Website muss dazu mit diesen Angaben mit einem Facebook-Account verknüpft werden:
Google Analytics und die Webmaster-Tools von Google, Bing oder Yahoo! wollen genauso verifiziert werden, bevor ihr Zugriff auf die Informationen erhaltet. Dies geschieht auch entweder über ein Meta-Tag oder über eine Datei, die im Root der Website ablegt wird. Um so viele unnötige Infos wie möglich im head-Bereich zu vermeiden, empfiehlt sich an dieser Stelle die Validierung per Datei.
Fazit
Heutzutage gibt es unzählige Möglichkeiten eine Webseite mit vielen – teilweise sehr speziellen – Informationen und Funktionen zu erweitern. Jeder Betreiber sollte sich aber sehr genau überlegen, welche Angaben sinnvoll sind und auf welche Spielereien besser verzichtet werden kann. Mit den vorgestellten Anregungen dieses Artikels lässt sich der head-Bereich der eigene Seiten nun nach individuellen Bedürfnissen optimieren.
Animationen können ein nützliches Werkzeug sein, um Interaktionen zu fördern und Informationen leichter verständlich zu machen. Doch wo viel Licht ist, ist auch viel Schatten. Ruckelnde Animationen mit geringer Framerate beeinträchtigen die Usability und wirken sich oft negativ auf das Nutzerverhalten aus. Mit ein, zwei Tricks könnt ihr die Performance der Animationen verbessern.
Animationen mit CSS
CSS3 bietet zwei Möglichkeiten, Inhalte zu animieren: Transitions und Keyframe Animationen.
Transitions sind Übergänge von einem Start- in einen Endzustand, Zwischenzustände sind hier nicht möglich. Sie haben zwei praktische Anwendungsbereiche: Zum einen sind Transitions sehr nützlich, um interaktive Zustandswechsel, zum Beispiel durch das Fokussieren eines Elements, zu animieren. Zum anderen eignen sie sich auch sehr gut im Zusammenspiel mit JavaScript, da Transitions auf jede Art von Styleänderungen (also durch inline Styles, Klassenzuweisungen oder Pseudoklassen) reagieren. → Beispiel ansehen
Sehr hilfreich ist außerdem, dass Transitions einen »eingebauten Fallback« besitzen: Browser, die keine Transitions kennen, führen denselben Zustandswechsel einfach abrupt durch. Das bedeutet, dass diese User dadurch keine bedeutenden Nachteile bei der Nutzung der Website haben.
Um jedoch eine optimale Performance bei Transitions zu erreichen, empfiehlt es sich, das Verhalten des Browsers etwas genauer unter die Lupe zu nehmen. Werden Eigenschaften, die sich auf das Layout einer Website beziehen (z.B. width/height, top/right/bottom/left, margin,…) geändert, so muss der Browser bei jeder Änderung das Layout der Seite neu berechnen. Schließlich ist es möglich, dass gefloatete Elemente durch die Änderungen umbrechen oder sich nachfolgende Elemente verschieben. Das Berechnen des Layouts ist ein vergleichsweise aufwändiger Prozess, der je nach Komplexität der Seite einige Millisekunden in Anspruch nehmen kann. Bei einmaligen Änderungen ist dies in der Regel kein Problem, aber bei Animationen können diese Millisekunden entscheiden, ob die Animation mit 60, 30 oder weniger Frames pro Sekunde abläuft und somit ruckelt. Dieses Problem könnt ihr jedoch umgehen, indem ihr statt Layout-Eigenschaften sogenannte CSS-Transformationen verwendet. Diese beziehen sich nur auf das jeweilige Element selbst und dessen Unterelemente, der Rest der Seite wird davon nicht beeinflusst und somit muss das Layout nicht neu berechnet werden. Ein weiterer Vorteil von CSS-Transformationen ist, dass diese auf Subpixel-Ebene arbeiten. Das heißt Elemente können auch um Bruchteile von Pixeln verschoben werden, wodurch die Pixel-Stufen umgangen werden können. → Beispiel ansehen
Weiterhin könnt ihr an der Performance-Schraube drehen, indem ihr einige Animationen vom Hauptprozessor (CPU) auf den Grafikprozessor (GPU) auslagert, der für grafische Berechnungen deutlich besser geeignet ist. Dies erreicht ihr im Moment durch den einfachen Trick, auch in der 2D-Ebene 3D-Transformationen zu verwenden. Dass sich die Animation trotzdem nur in zwei der drei Dimensionen bewegt, stört schließlich niemanden. Die meisten Browser lagern diese »komplexeren« Berechnungen dann auf die schnellere GPU aus. Leider können 3D-Transformationen allerdings Seiteneffekte hervorrufen und zu einem Flackern der Seite oder ähnlichen Problemen führen. Glücklicherweise werden zukünftig aber auch 2D-Transformationen auf die GPU ausgelagert, sodass der Umweg über die dritte Dimension nicht mehr gegangen werden muss. Einen umfassenden Artikel zur Hardwarebeschleunigung in CSS hat Martin Kool bei Smashing Magazine veröffentlicht.
Keyframe Animationen sind die zweite Möglichkeit, Animationen mittels CSS zu realisieren. Sie eigen sich besonders, wenn sich Animationen selbstständig, ohne Eingreifen des Users, ablaufen sollen. Gegenüber Transitions haben sie außerdem den Vorteil, dass komplexere Abläufe mit Zwischenzuständen definiert werden können. → Beispiel ansehen
Natürlich spielt aber auch hier das Rendering-Verhalten des Browsers eine Rolle, sodass ihr die bei den Transitions erwähnten Tricks hier ebenso anwenden könnt.
Doch diese beiden Techniken alleine werden zur Umsetzung komplexerer Animationen, bei denen zum Beispiel mehrere Elemente in Abhängigkeit voneinander animiert werden müssen, nicht ausreichen. Zum Glück gibt es da aber noch JavaScript, mit dessen Hilfe ihr auch diese Animationen in den Griff bekommt.
Animationen mit JavaScript
Für komplexe Animationen solltet ihr weiterhin auf JavaScript zurückgreifen, da Animationen mit vielen Abhängikeiten mit den oben genanten Methoden zwar möglich, aber unnötig kompliziert sein können. Auch hier hat sich in letzter Zeit einiges getan, um eine bessere Performance zu erreichen. Die bisherige Strategie, Eigenschaften mit einem festgelegten Intervall alle paar Millisekunden zu ändern, hat ausgedient und dient heutzutage nur noch als Fallback für ältere Browser. Fast alle aktuellen Browser können mit der Methode requestAnimationFrame umgehen, die unnötige Berechnungen verhindert und somit die CPU und den Akku schont, was vor allem auf mobilen Geräten sehr wichtig ist. Der Trick dabei ist, dass der Browser angibt, wann er die Seite neu rendern kann und Eigenschaften somit nur dann neu berechnet werden müssen, wenn diese auch verwendet werden. Die praktische Anwendung von requestAnimationFrame wird in einem Artikel von Paul Irish thematisiert.
Fazit
CSS3 und JavaScript bieten gute Möglichkeiten, Animationen performant umzusetzen. Dennoch sollten sich Entwickler immer klar darüber sein, dass Animationen denselben Effekt wie eine Latenz haben: Der User muss warten. Deshalb gilt auch hier oft der allgemeine Satz »weniger ist mehr«. Animationen sind gut geeignet, um Übergänge leichter verträglich zu machen und können auch optisch ein Pluspunkt sein, wenn man sie richtig einsetzt. Wer allerdings alles wild durcheinander bewegt, der wird dem User schnell den Überblick nehmen und diesen verärgern. Deshalb: Keep it simple!
Bei größeren Webprojekten kann es schwierig, sogar hinderlich sein, im Voraus festzulegen, was am Ende wirklich benötigt wird. Agile Entwicklungsmethoden bieten einen anderen Ansatz: Mit wenigen Regeln und einem iterativen Vorgehen sollen die Projekte flexibler und einfacher werden. Methoden und Ideen wie Sprints, User Stories und Kanban Board eignen sich auch für kleinere Teams und Projekte.
Kanban und Scrum sind agile Vorgehensmodelle, die sich gegenwärtig großer Aufmerksamkeit erfreuen und seit Jahrzehnten erfolgreich eingesetzt werden – sowohl im Großen bei Weltkonzernen wie Toyota als auch auf individueller Ebene zur Selbstorganisation.
Unzählige Schulungsangebote, Fachvorträge und Bücher bieten einen guten Einstieg in die Methoden und deren Umsetzung in Entwicklungsteams oder ganzen Unternehmen. Anstelle einer weiteren Einführung in die Methoden findet ihr im Folgenden einen Überblick über die »agilen« Ideen und Werkzeuge sowie deren mögliche Anwendungen in der täglichen Arbeit – in Form einer Kombination von Kanban und Scrum. Diese bietet insbesondere für einzelne Webworker oder kleine Teams eine Chance, die Vorteile auch im »nicht-agilen« Umfeld zu nutzen.
Verbesserung in kleinen Schritten
Der Kern der beiden Vorgehensweisen – das Agile Manifest– hat folgende Kernaussagen:
Individuen und Interaktionen sind wichtiger als Prozesse und Werkzeuge.
Funktionierende Software ist wichtiger als umfassende Dokumentation.
Zusammenarbeit mit dem Kunden ist wichtiger als Vertragsverhandlung.
Schnelle Reaktion auf Veränderung ist wichtiger als die strikte Planung.
Das bedeutet nicht, dass Prozesse, Werkzeuge, Dokumentation, Vertragsverhandlungen und ein Projektplan unwichtig oder unnötig wären. Es geht mehr um die richtigen Prioritäten.
Insbesondere Kanban legt großen Wert darauf
Prozesse zu standardisieren und kontinuierlich zu verbessern.
Fehler zu vermeiden und die Kosten von Fehlern zu reduzieren.
Im Kundentakt zu produzieren (nur das, was der Kunde wirklich benötigt, bei kontinuierlicher Anpassung der Planung an geänderte
Anforderungen).
Verschwendung zu reduzieren.
Es wird versucht, die Welt des Kunden mit dessen Augen zu sehen:
Denken wie der Kunde beziehungsweise der Nutzer.
Direkte Kommunikation zwischen den Entwicklern und dem Kunden.
Priorisierung von Entwicklungszielen anhand ihres Wertes für den Kunden.
Zeitnahe Lieferung und Verifizierung von Zwischenständen.
Die Werte sind daher Offenheit, Verantwortung und Einfachheit.
Die Kundenzufriedenheit wird hierbei durch einen kontinuierlichen und institutionalisierten Dialog gesteigert; die Entwicklung bewegt sich dabei »von 100% unbekannt« hin zu »100% fertig«. Änderungen an der Planung werden genauso berücksichtigt (und sind willkommen/eingeplant) wie die regelmäßige Lieferung fertiger Softwarestände.
Einfachheit
Das wichtigste Ziel agiler Methoden ist die Einfachheit. Viele Entwickler neigen dazu, technisch komplizierte Lösungen und interessante Zusatzfunktionalitäten zu entwickeln, die zur Lösung des Problems gar nicht benötigt werden. Die Vorteile der »einfachsten Lösung«:
Es muss weniger Code produziert werden.
Es muss weniger Code getestet werden.
Weniger Funktionalität und Komplexität bedeutet meist eine einfachere Nutzung, geringeren Schulungsaufwand, was zu einer höheren Zufriedenheit bei den Nutzern führt.
Die Komplexität der Lösung ist geringer, dadurch sinkt die Wahrscheinlichkeit, auf unerwartete Probleme zu stoßen.
Die Gesamtkosten aus Sicht des Kunden sinken (Stichwort: »total cost of ownership«), da in Zukunft auch weniger Code gewartet werden muss.
Das Projekt wird schneller fertig.
Daher führen weniger Funktionen und einfachere Lösungen fast automatisch zu zufriedeneren Kunden und Nutzern. Wie kann dies nun in der Praxis umgesetzt werden?
User Stories und Product Backlog – oder: »was soll entwickelt werden?«
Als User Story wird eine in Alltagssprache formulierte Anforderung aus Nutzersicht bezeichnet. User-Stories sollten in ein bis zwei Sätze gefasst werden und möglichst auf eine Karteikarte passen. Es ist sinnvoll, innerhalb eines Projektes eine einheitliche Struktur für User Stories zu wählen. Ein Beispiel mit dem Fokus auf die Benutzerrolle (zum Beispiel »Besucher der Webseite«, »Editor«): »Als <Rolle> möchte ich <Ziel/Wunsch>, um <Nutzen> zu erreichen.«
»Als Besucher der Webseite möchte ich dem Betreiber eine Nachricht zukommen lassen, um weitere Informationen zu einem Produkt anzufordern«.
»Als Besucher der Webseite möchte ich dem Betreiber eine Nachricht zukommen lassen, um einen Termin auszumachen«.
»Als Betreiber der Website möchte ich Nachrichten von Besuchern der Webseite als E-Mail erhalten, um direkt darauf reagieren zu können«.
In User Stories werden Ziele und Nutzen aus Sicht des Anwenders beschrieben, statt sich bereits auf eine Funktionalität und Implementierung zu begrenzen. Anstelle von »wie umsetzen« wird beschrieben was erreicht werden soll. Die Frage nach dem Ziel erleichtert es zudem, ungeeignete oder unnötig komplizierte Funktionalitäten leichter zu identifizieren, da der Nutzen des Anwenders klar im Vordergrund steht. Das gleiche gilt für Spielereien und subjektive Präferenzen. Folgende User Stories sind schwerlich vorstellbar:
»Als Besucher der Webseite wünsche ich mir, dass Musik im Hintergrund gespielt wird, weil ich das total toll finde«
»Als Besucher der Webseite wünsche ich mir, dass wichtige Textstellen unterstrichen sind, damit ich mir diese besser merken kann«
»Als Besucher der Webseite möchte ich gefragt werden, bevor ich die Webseite schließen kann, damit ich nochmals bestätigen kann, ob ich wirklich die Seite verlassen will«
User Stories reduzieren Komplexität. Insbesondere zu Anfang eines Projektes sind viele Anforderungen noch sehr abstrakt. Kundenziele, die auf einer horizontalen Achse den gesamten Umfang des Projektes beschreiben, können durch weitere Verfeinerung in vertikaler Richtung immer detaillierter beschrieben werden.
Größere Themenblöcke werden als »Epic« bezeichnet. Dies können zum Beispiel Funktionalitäten wie Authentifizierung, die Nutzung eines Kontaktformulars oder die Anmeldung zu einem Newsletter sein. Aus »Als Besucher der Webseite möchte ich mich zu einem Newsletter anmelden, um eine Mail zu erhalten, sobald es Neuigkeiten gibt« (Epic) können dann weitere User Stories abgeleitet werden, die insbesondere aus Sicht verschiedener Nutzergruppen oder Bestandteile des Systems formuliert werden.
Praxistipps zur Strukturierung:
User Stories sollten eine eindeutige Identifikationsnummer haben, um leicht in Bezug zueinander gesetzt werden zu können.
Beispiel: »Siehe auch: #2456, #3322« oder »Blockiert: #994, #4110«.
Zur leichteren Strukturierung bietet es sich an, eine Überschrift mit Modulzuordnung zu verwenden. Beispiel:
User Story: »Um mich zum Newsletter anzumelden, möchte ich als Besucher der Webseite meine E-Mail-Adresse angeben können«.
Neben Epic und User-Stories gibt es noch Task (Aufgabe). Eine Task beschreibt die konkrete Umsetzung und somit das »wie« einer User Story. Beispiel:
Orderstruktur und CSS Dateien anlegen.
jQuery dem Projekt hinzufügen.
Als »Product Backlog« wird die Summe aller Epics, User-Stories und Tasks beschrieben, die das zu entwickelnde Produkt beschreiben.
Sprint Backlog und Kanban-Board
Im Scrum-Prozess erfolgt die Umsetzung in sogenannten »Sprints« – in sich geschlossene Zyklen – die üblicherweise eine Länge von zwei Wochen haben. Je nach Team, Projekt oder auch Projektphase sind natürlich auch kürzere oder längere Intervalle möglich. Insbesondere während der Einführung von Scrum kann es sinnvoll sein, für eine begrenzte Zeit im Wochenrhythmus zu arbeiten, um Erfahrungen zu sammeln und den Prozess zu etablieren.
Die Srum-Projektmanagement-Methode
Sehr stark vereinfacht besteht ein zweiwöchiger Sprint (10 Arbeitstage) aus folgenden Phasen:
Planung (5 Tage vor Sprintbeginn)
Auswahl der User Stories für den Sprint
Priorisierung der User Stories
Aufwandsschätzung für die einzelnen Aufgaben
Kick-Off – Detailplanung (1. Tag)
Umsetzung (2. bis 9. Tag)
Präsentation der Ergebnisse in einer »Sprint Demo« (10. Tag)
Scrum ist ein sehr stark regulierter und strukturierter Prozess (circa 35 Regeln), mit sehr detaillierten Beschreibungen von Rollen und Verantwortlichkeiten.
Einige dieser Regeln lauten:
Die Anzahl der zu erreichenden Ziele wird vor dem Sprint festgelegt. Muss während des Sprints eine Änderung vorgenommen werden, erfolgt dies durch einen sogenannten »Change Request«. Für jede zusätzliche Aufgabe wird eine mit vergleichbarem Aufwand aus den Sprintzielen entfernt. Für das Team stellt dieses Vorgehen eine zentrale Schutzfunktionen dar.
Am Ende des Sprints steht immer ein nutzbares Arbeitsergebnis, das wiederum als Grundlage für die nächste Sprintplanung dienen kann. Konkret bedeutet das: Funktionalitäten so früh wie möglich nutzbar machen, um authentisches Feedback sammeln zu können.
Die gleichbleibende Länge der Sprints ermöglicht eine gewisse Plan- und Vorhersagbarkeit der folgenden Sprints, da eine Metrik für die Team Geschwindigkeit (Velocity) abgeleitet werden kann. Im einfachsten Fall könnte dies »Anzahl der Stories / Sprint« sein, wobei aus vergangenen Erfahrungen natürlich immer nur begrenzt auf die Zukunft schließen lässt.
Kanban hat im Vergleich zu Scrum nur wenige Regeln. Die zentralen Ideen lauten:
Visualisierung des Arbeitsprozesses.
Begrenzung der Anzahl gleichzeitiger Aufgaben (»Work in Progress« - WiP).
Zentrales Element ist das »Kanban Board«: Es umfasst verschiedene Spalten, welche die einzelnen Prozessschritte abbilden. Beispiel:
Todo: Alle zu erledigenden Aufgaben
In Bearbeitung
Fertig
Ein etwas detaillierteres Board in der Programmierung mit acht Schritten könnte so aussehen:
Backlog
Umsetzung
Programierung
Programmierung fertig
Verifizierung
Abnahme- und Akzeptanztests
Testen
Tests fertig
Auslieferung
Kanban begrenzt dabei die Anzahl der gleichzeitig offenen Aufgaben im Status Bearbeitung (WiP) um eine Überlastung zu vermeiden. Wie würde also eine Verbindung der beiden Ansätze in der Praxis aussehen? Scrum lässt sich als Rahmen verwenden, um das Backlog zu strukturieren und Ziele für ein Team zu definieren, um dann die persönlichen Aufgaben für jedes einzelne Teammitglied mittels eines Kanban Boards zu organisieren. Ein Beispiel für ein Team aus jeweils einem Redakteur, Designer, Frontend- und Backend-Entwickler:
Sprint Länge: zwei Wochen.
Jedes Teammitglied erhält ein persönliches Kanban Board.
Die beiden Entwickler sind Vollzeit im Projekt verfügbar.
Die beiden Entwickler werden mit netto 40 (von ca. 75 möglichen) Arbeitsstunden im Sprint geplant, um über ausreichend Puffer zu verfügen.
Die Entwickler bearbeiten gemeinsam das Sprint Backlog, aber strukturieren ihre persönlichen Aufgaben auf jeweils eigenen Kanban Boards.
Der Redakteur wird im Scrum je Sprint flexibel eingeplant, wobei dies zwischen 0% zum Projektstart und 100% zum Projektende (Testen) variiert. Sein Kanban Board umfasst auch andere Projekte und berücksichtigt insbesondere täglich neu auftretende Aufgaben im Kontakt mit dem Kunden.
Notwendige Zulieferungen des Designers müssen vor Beginn des jeweiligen Sprints vollständig vorliegen, weshalb diese nicht im Scrum geplant werden.
Der Designer profitiert durch die Visualisierung seiner Aufgaben durch ein Kanban Board insbesondere, da er jederzeit »zeigen« kann, woran er gerade arbeitet. Darüber hinaus unterstützt die Begrenzung des WiP den kreativen Prozess.
Die Sprint Demo bringt alle Beteiligten zusammen und ermöglicht, die Arbeitsergebnisse zu diskutieren.
Im morgigen zweiten Teil geht es um den Praxiseinsatz, Werkzeuge und die Frage, wie ein Vertragsentwurf für ein agiles Projekt aussehen könnte.
Wenn sich Kunde und Auftraggeber einig sind und auf einen agilen Prozess einlassen, stellen sich automatisch einige Fragen: Wie funktioniert das System nun im realen Projekt? Wie lässt sich diese Umsetzung kalkulieren? Und wie wird das im Vertrag festgehalten?
Im ersten Teil ging es um die grundlegenden Ziele und Methoden agiler Entwicklung. Dazu kommen nun verschiedene Positionen im Team, Werkzeuge sowie feste Elemente in agilen Prozessen:
Product Owner, Scrum Master und das Team
Im Scrum Prozess obliegt es dem sogenannten »Product Owner«, die Kundenbedürfnisse zu repräsentieren und die Einträge im Backlog nach diesen zu priorisieren. Der »Scrum Master« trägt die Verantwortung für die Einhaltung der Scrum-Regeln, Moderation von Meetings und Lösung von Problemen, die Fortschritte des Teams behindern (»Blocker«). Eine detaillierte Beschreibung der Rollen und ihrer Aufgaben sprengt den Rahmen dieses Artikels. Bei Verwendung der Methoden zur persönlichen Organisation oder zur Strukturierung der Aufgaben in kleinen Teams ist es ohnehin eher fraglich, inwiefern die »reine Lehre« von Scrum angewendet werden kann oder sollte.
Empfehlenswerte Werkzeuge
Meiner persönlichen Erfahrung nach ist es nicht sinnvoll, spezielle Softwarelösungen für agile Prozesse einzusetzen. Sie beschränken in der Regel die Möglichkeit, den Prozess an die
eigenen Bedürfnisse anzupassen. Eine Mischung der folgenden Werkzeugen halte ich für sinnvoller:
Ein Board, um Karteikarten mit Epics / User Stories zu befestigen. Für eine Übersicht über das Product Backlog und wichtige Meilesteine / Termine, eher vergleichbar mit einer
Roadmap.
Das vollständige Product Backlog in digitaler Form, zum Beispiel als Tabelle (etwa Excel, Open Office, google docs) oder in einem einfachen Ticketsystem (zum Beispiel
redmine).
Das Sprint Backlog: entweder als eigenständiges Text-Dokument oder als Zuweisung einer Zielversion in Redmine. Es ist darüber hinaus sehr sinnvoll, in Form von Karteikarten auf einem weiteren Board für alle Beteiligten eine Visualisierung vorzunehmen, in Sprint Backlog – in Bearbeitung – Fertig.
Ein Kanban Board für jedes Mitglied im Team, das mindestens einmal am Tag aktualisiert wird.
Daily Standup Meeting
Ein fester Bestandteil im Scrum-Prozess ist das sogenannte »Daily Standup Meeting«. Zu einer festgelegten Zeit (möglichst zu Anfang des Arbeitstages) trifft sich das Projektteam. Jedes Teammitglied gibt dabei einen kurzen Statusbericht ab:
Was habe ich gestern getan?
Was werde ich heute tun?
Benötige ich Unterstützung? Was blockiert mein Fortkommen?
Ziel ist es, den Wissensstand aller Beteiligten abzugleichen, Probleme frühzeitig zu identifizieren und transparent zu kommunizieren, wer gerade an welcher Aufgabe arbeitet. Die wichtigsten Aspekte des Daily Standup:
Findet wirklich im Stehen statt, um möglichst dynamisch und kurz zu bleiben.
Ist sehr kurz (weniger als eine Minute pro Person).
Dient nicht als Diskussionsforum.
Benötigt Moderation (zumeist durch den Scrum-Master).
Als Vorbereitung auf den Daily Standup sollte sich jedes Teammitglied Gedanken über die an diesem Tag anstehenden Aufgaben gemacht haben. Als einfache und sehr effektiv Methode
hat sich dabei bewährt, die Aufgaben schriftlich nach Priorität auf einem Blatt Papier festzuhalten. Selbstverständlich bildet ein gepflegtes Kanban Board genau diese Funktion ab. Es ist jedoch nicht immer praktikabel, alle Boards zum Standup Meeting mitzubringen.
Retrospektiven und Kaizen
Ein weiteres zentrales Element agiler Prozesse sind regelmäßige Überprüfungen des Prozesses selbst. Im Scrum Prozess ist hierfür in jedem Sprint ein »Retrospective Meeting« vorgesehen, um den Prozess zu reflektieren. Jedes Teammitglied bereitet dafür vorab Antworten auf die folgenden drei Fragen vor:
Was ist gut gelaufen / wovon sollten wir »mehr« tun?
Was ist schlecht gelaufen / was sollten wir »weniger« tun?
Wie können wir konkret eine Verbesserung einführen?
Generell finden sich zum Thema kontinuierliche Verbesserungsprozesse oder Kaizen zahlreiche erprobte Ansätze, die sich auf die Arbeit des Teams und die Arbeitsumgebung anwenden lassen. Wichtig ist, für diese Art der Prozessverbesserung genügend Zeit einzuplanen und die Umsetzung von Verbesserungen auch konsequent zu verfolgen. Ansonsten droht die Gefahr, dass Retrospektiven zu reinen Pflichtveranstaltungen ohne Wert für die Beteiligten verkommen und früher oder später als Zeitverschwendung betrachtet werden.
Exkurs: Projektarbeit – der Vertrag
Agile Verträge bergen zahlreiche Fallstricke. Dieser Artikel soll, kann und darf keine Rechtsberatung darstellen.
In der Praxis kann oftmals eine klassische Vorgehensweise als »einfacher« verkauft werden. Diese Erfahrung schlägt sich dann auch im Angebot nieder – ein möglicher Rahmen ist also ein (Wasserfall-)Werkvertrag, der dann explizit definiert, dass dieses Projekt in Stufen umgesetzt wird und agile Elemente aufgreift. Mögliche Stufen:
Planung
Gemeinsame Definition der Projektziele
»content first« Ansatz
Entwicklung einer visuellen Formensprache (»Design«)
Umsetzungsphase (Scrum Prozess)
Umsetzung einer ersten Version
Hinzufügen von Funktionen in kurzen Zyklen
Verifizierung der Umsetzung
Einführung
Schulung
Finalisierung von Inhalten
Auslieferung
Agile Kalkulation
Erwartungsgemäß »fixe« Kosten wie Konzeption, Design, Installation von Softwarekomponenten, Schulung und Auslieferung können aufgrund einer Anforderungsanalyse und Erfahrungenswerten aus der Vergangenheit gut kalkuliert werden. Für den agilen Teil könnte jetzt ein »fixes« Zeitkontingent angeboten werden. Wobei dies wirklich als Budget betrachtet werden sollte, da in enger Abstimmung mit dem Kunden dann während der Umsetzung der Umfang und die Verwendung angepasst werden. Ziel ist es, das Projekt gemeinsam mit dem Kunden vertrauensvoll und transparent zu realisieren. Dies ist möglich, wenn der Kunde jederzeit klar erkennen kann, wofür sein Geld verwendet wird, welchen Gegenwert er erhält, und an welchem Punkt der Entwicklung sich das Projekt befindet.
Wieso sollte sich ein Auftraggeber auf eine agile Vorgehensweise einlassen?
Priorisierung der Projektziele durch den Kunden anhand des Wertes (sowohl aus Unternehmens- als auch Nutzersicht).
»Nutzbare« Version der Software ab der ersten Iteration. Hierdurch sinkt das Risiko von kostspieligen Fehlentwicklungen.
Eine Neupriorisierung ist als Teil des Prozesses jederzeit möglich.
Weitere Ideen in der Zusammenfassung
Ziel agiler Vorgehensmodelle ist es, wertige Ergebnisse zu produzieren. Hierfür kommen unter anderem auch folgenden Ideen zum tragen:
Das Pull-Prinzip: Ein Mitarbeiter arbeitet nur an Aufgaben, für die er und die nachfolgenden Prozessschritte genügend Ressourcen haben.
Pareto-Prinzip (80/20): 80% der Ergebnisse benötigen 20% der Zeit – und die restlichen 20% der Ergebnisse 80% der Zeit. In Zusammenhang mit einer Betrachtung des Wertes einer
Funktionalität kann die konsequente Anwendung dieser Idee bereits während der Projektplanung dazu führen, dass Überschreitungen des Zeit- und Budgetrahmens erkannt und dann
vermieden werden können.
Qualität ist Bestandteil des Prozesses – zum Beispiel in Form von Test Driven Design (TDD).
Minimierung von Risiken durch kleine Schritte: Funktionalitäten sollten möglichst innerhalb eines Sprints realisiert werden, Arbeitspakete innerhalb eines Tages.
Überflüssige und nutzlose Features durch das KISS-Prinzip (Keep it simple stupid!) vermeiden: »so einfach wie möglich halten«.
Nur umsetzen, was jetzt wirklich benötigt wird: Yagni Prinzip oder auch Just-In-Time-Implementierung.
Features, die lange im Backlog liegen, sind in der Regel überflüssig (Stichwort: Backlog Grooming).
Das Konzept »Technische Schulden« beachten: Je länger die Lösung aufgeschoben wird, desto höher die Kosten der Lösung.
Als letzer Aspekt kann noch der Wissensaufbau und Transfer betrachtet werden. Beispiele hierfür sind:
Synchrones & asynchrones Pair-Programming.
Systematischer Erwerb von theoretisches Wissens zum Beispiel durch Weiterbildung, Besuch von Konferenzen, regelmäßige interne Vorträge.
Vermeidung von Insel-Know-How.
Grenzen agiler Methoden
Meine persönliche Meinung ist: Agile Vorgehensmodelle sind nicht automatisch besser. Unzählige Beispiele aus der in der Praxis zeigen, dass Produktivität und Zufriedenheit aller Beteiligten sinken kann, wenn der agile Prozess nicht konsequent befolgt und gelebt wird.
Es lohnt sich in jedem Fall, sich intensiver mit dem Thema auseinanderzusetzen und zumindest einzelne Elemente zu verwenden, selbst wenn eine Umsetzung kompletter Prozesse nicht ratsam erscheint, zum Beispiel weil auf Kundenseite noch keine Bereitschaft besteht, sich darauf einzulassen. Bereits die Verwendung einzelner Elemente wie Daily Standup Meetings, Planung mit User Stories, Planungsboards nach Kanban oder regelmäßige Retrospektiven können einen großen positiven Einfluss auf die persönliche Zufriedenheit für alle Beteiligten haben. Und nicht zuletzt den Projekterfolg.
Zum Abschluss des diesjährigen Adventskalenders haben wir die Webkrauts gefragt: »Wenn du jeden Webworker zwingen könntest, ein Fachbuch zu lesen: Welches wäre das?«
»Der Web-Report« Tim Berners-Lee, Econ (1999)
1988 begann ein am CERN-Institut angestellte Informatiker namens Tim Berners-Lee mit der Arbeit an einem neuen Hypertext-Dokumentationssystem. Es sollte dezentralisiert sein und so von möglichst vielen Nutzern auf möglichst vielen Systemen verwendet werden zu können. Das System nannte er »World Wide Web«. Er startete mit der Programmierung eines Browsers. Anschließend schrieb er den Code für das Hypertext Transfer Protocol (HTTP), über das Computer über das Internet kommunizieren würden, sowie den Universal Resource Identifier (URI), das Schema, nach dem Dokumentadressen erstellt und aufgefunden werden können. Im Dezember 1990 arbeitete er an seiner Hypertext Markup Language (HTML), darüber hinaus programmierte er einen eigenen kleinen Webserver.
Einige Jahre später, 1999, war das World Wide Web bereits etabliert und Berner-Lee blickte zurück und schrieb sein Buch »Der Web-Report«. 1999, also in dem Jahr, in dem Yahoo! noch eine große Nummer war; in dem wir HTML 4 gesprochen haben; als Microsofts Internet Explorer den Browserkrieg bereits gewonnen und den Netscape Navigator auf einen Marktanteil von vielleicht noch 40% zurück gedrängt hat – alles ist unglaublich lange her, aber genau das macht Berners-Lees Buch so faszinierend.
Auf dem Buchrücken bezeichnet Michael L. Dertouzos, damals Direktor des M.I.T. und mittlerweile verstorben, das Buch als »einzigartige Geschichte über eine einzigartige Erfindung, geschrieben von ihrem genialen Erfinder«. Das trifft es ganz gut. Aus meiner Sicht eine Pflichtlektüre für jeden der ... ach, eigentlich tatsächlich für jeden.
Michael Jendryschik
»Don't Make Me Think: A Common Sense Approach to Web Usability« Steve Krug, New Riders (2009; 2013)
»Don't Make Me Think« ist das Buch über Web-Usability und gehört zur Pflichtlektüre für alle, die beruflich im Web arbeiten – seien es Designer, Entwickler, Konzepter oder Entscheider. Dass sich diese Erkenntnis noch nicht vollständig verbreitet hat, sehen wir leider tagtäglich um uns herum: Von Texten, die mit viel heißer (Marketing-)Luft gefüllt sind, über umständliche Online-Bestellformulare bis hin zur frustrierenden Bedienung von Ticket-Automaten.
Dieses Buch gibt eine gute Übersicht über Usability im Allgemeinen, wie man verständlich fürs Web schreibt, Navigationen entwirft und vieles mehr. Dazu kommen nützliche Alltagstipps bei typischen Problemen wie »Hilfe, mein Chef will, dass ich __________ mache!«.
Ein kleiner Tipp: Ende Dezember kommt die überarbeitete dritte Auflage auf den Markt, dann auch (laut Cover) mit einem Kapitel zu Usability für Mobile.
Frederic Hemberger
»Clean Code: A Handbook of Agile Software Craftsmanship« Robert C. Martin, Prentice Hall (2008)
Robert C. Martin, im Netz auch »Uncle Bob« genannt, ist sozusagen der »Godfather of Software Craftsmanship«, einer immer größer werdenden Bewegung, die Softwareentwicklung als Handwerk begreift. Dazu gehört auch das Bewusstsein, wie man seine Arbeitsweise kontinuierlich verbessert und sein Handwerk mit der Zeit besser beherrschen lernt. Denn auch in unserer »Zunft« gibt es Kunstschreiner und Ikea-Schrauber.
»Clean Code« ist eine der Grundlagen dazu: Was unterscheidet guten Code von schlechtem Code? Wie erkenne ich »code smell«? Wie benenne ich Variablen, Funktionen und Objekte so, dass sie wirklich exakt ihre Aufgabe beschreiben und mein Code verständlicher wird? Wie kann ich meinen Code zuverlässig testen?
Das Buch führt den Leser in verständlicher und unterhaltsamer Weise an das Thema heran. Auch wenn die Code-Beispiele in Java geschrieben sind und das zunächst abschrecken mag: Die Inhalte gelten für alle Sprachen, auch wenn sich die Art der Implementierung oder sich die Gewichtung der vorgestellten Konzepte unterscheiden mag. Wer sich schon einmal grundlegend mit anderen Programmiersprachen beschäftigt hat, wird sich sehr schnell zurecht finden.
Daher meine Leseempfehlung: Bessere Programmierer werden immer gebraucht!
James Kalbach schreibt ein ganzes Buch über Naviagtionen, ohne eine einzige Zeile Code dazu zu veröffentlichen. Ihm geht es darum, die vielfältigen Ausdrucksformen und Vorkommen von Navigationen zu beleuchten, ihre Usability zu beschreiben. Er sensibilisiert den Leser für einen ganz zentralen Bestandteil einer Webseite. Denn wie soll der Nutzer von einer Seite zur anderen kommen, wenn nicht durch eine Navigation?
Als ich das Buch das erste Mal in der Hand hielt, konnte ich mir kein interessantes Thema dahinter vorstellen. Doch ich war schnell gefesselt. Auch von den facettenreichen Beispielen, die der Autor aus der ganzen Welt nimmt. Nicht nur aus den USA oder Europa. Leider gibt es das Buch nicht mehr bei O'Reilly auf Deutsch. Eventuell findet es sich irgendwo als Restposten. Es heißt dann »Handbuch der Webnavigation« und ist jeden Cent und jede Leseminute wert.
Jens Grochtdreis
»Designing with Progressive Enhancement« Todd Parker, Patty Toland, Scott Jehl und Maggie Costello Wachs, New Riders (2010)
Dieses Buch ist für mich zu einem absoluten Klassiker geworden. Es ist zwar nicht mehr ganz neu, beschreibt aber eindrucksvoll und nachhaltig die Paradigmen der Webstandards. Progressive Enhancement ist ein Garant für Accessibility, Performance und letztlich auch technische Suchmaschinenoptimierung. Das Buch zeigt anhand von praktischen Beispielen die Konzipierung von Fallbacklösungen auf, wie WAI ARIA richtig eingesetzt wird und Best Practices für den Einsatz von HTML(5) und CSS(3) aussehen. Eine Pflichtlektüre für jeden Frontendentwickler und sicher auch noch in ein paar Jahren aktuell.
Henry Zeitler
»Scalable and Modular Architecture for CSS – SMACSS« Jonathan Snook (2011)
»Das Frontend? Och, das ist doch nur ein bisschen HTML und CSS«. Diese Aussage habe ich im Laufe der Zeit zu oft gehört und jedes Mal antworte ich: »Das erklärt dann auch, warum da draußen nur Websites existieren, die nett anzusehen und technisch einwandfrei sind?«. Genau aus diesem Grund liebe ich Bücher wie SMACSS.
SMACSS hebt die oft unterschätzten Stylesheets auf einen Level, den sie verdienen und zeigen, dass sie es Wert sind, ihnen eine eigene Logistik und Architektur zuteil werden zu lassen. Gut organisierte Stylesheets sorgen für eine bessere Performance, Wartbarkeit und Nachhaltigkeit der Website. Dieses Buch zeigt einen möglichen Weg, Stylesheets zu organisieren, und wie wichtig es ist dieses zu tun. Dabei muss der Leser die vorgeschlagene Architektur von Jonathan Snook nicht exakt so übernehmen, es reicht völlig aus, sich einfach nur inspirieren zu lassen. Und das Beste ist, es ist auch als kostenloses Online-Book erhältlich.
Henry Zeitler
»Das Design-Buch für Nicht-Designer: Gute Gestaltung ist einfacher, als Sie denken!« Claudia Korthaus, Galileo Design (2013), 330 Seiten
Dieses Buch bietet einen umfangreichen Einstieg in das Thema Grafikdesign. Der Themen-Schwerpunkt liegt im Grafikdesign, mit einem besonderen Fokus auf Formen, Auswahl von Schriften und Farbpaletten. Zahlreiche Praxisbeispiele und eine passende, sehr visuelle Art der Wissensvermittlung runden den Inhalt gekonnt ab.
Die Lektüre ist besonders empfehlenswert für Programmierer, Texter, Projektleiter und auch Kunden, um den Blickwinkel eines Designers zu »verstehen« und um eine gemeinsame Sprache und ein gemeinsames Verständnis zu entwickeln.
Bernhard Welzel
»Visuelle Intelligenz« Donald D. Hoffman, Klett-Cotta (2001)
Einem dreizehnjährigen Jungen wird zu Beginn des 18. Jahrhunderts der angeborene graue Star gestochen, er kann plötzlich sehen. Der Junge denkt zuerst, die nun sichtbaren Objekte der Welt berühren direkt seine Augen. Anschließend lernt er, Dinge anhand des Aussehens zu unterscheiden. Es dauert aber noch zwei Monate, bis der Junge lernt, die gesehenen Objekte nicht als unterschiedliche Ebenen mit unterschiedlichen Farben wahrzunehmen, sondern als dreidimensionale Objekte.
Dieses Beispiel stammt aus dem Buch Visuelle Intelligenz: Wie die Welt im Kopf entsteht vom US-amerikanischen Wissenschaftler Donald D. Hoffman, meine Empfehlung vor allem für Designer und Konzepter. Kurz gesagt, beschreibt das Buch, wie unser Gehirn lernt, das Bild der Welt zu erschaffen. Jeder kennt das Sprichwort »Ein Bild sagt mehr als tausend Worte«, aber kaum jemand weiß genau, warum das eigentlich so ist. Als Leser erfährt man anschaulich, präzise und auch noch recht unterhaltsam, dass es den unbefangenen Betrachter nicht gibt, dass wir vielmehr mit Hilfe unseres Gehirns gelernt haben, unsere Welt so wahrzunehmen, wie wir sie mit Hilfe unserer Augen sehen. Hoffman zeigt nicht nur bekannte und weniger bekannte optische Täuschungen, er erläutert auch, warum wir uns täuschen lassen und welche Funktion diese Wahrnehmungen für unser Leben und Überleben im Laufe der Evolution hatten und noch immer in unserem täglichen Leben haben.
Interessant ist das Buch auch für die Gestaltung im Webdesign, da hier auch Grundlagen wie Figur-Grundbeziehungen, Abstand und Nähe von Objekten, Flächenwirkungen und dreidimensionale Effekte verständlich erklärt werden.
Nils Pooker
»Flexible Boxes« Peter Müller, Galileo Press (2013)
Peter Müllers Buch richtet sich zwar nicht an gestandene Entwickler, dennoch sollte es als Pflichtlektüre dessen betrachtet werden, was man als gestandener Webdesigner und -entwickler wissen sollte.
Peter Müller ist seit seinem Bestseller »Little Boxes« bekannt für seinen unterhaltsamen und kurzweiligen Schreibstil, sein Buch Flexible Boxes macht keine Ausnahme. Der Titel könnte zwar nahelegen, hier handele es sich um eine Einführung zum Thema Responsive Webdesign, inhaltlich umfasst es jedoch weit mehr. Als Leser erfährt man angenehm zusammengefasst die Grundlagen zu HTML5, CSS3 und Responsive Webdesign. Innerhalb dieser Bereiche werden diejenigen Aspekte näher erläutert, die für die Praxis moderner Webentwicklung wichtig sind, beispielsweise Grid-Systeme, CSS-Frameworks, der Einsatz von Media Querys, Gestaltung von Formularen und die Einbindung von Webfonts.
Allein diese zusammenfassende Darstellung in Verbindung mit der bewährt hohen Schreibqualität von Peter Müller macht das Buch zu einer sinnvollen Ergänzung der Standardwerke zum Webdesign, denn als Webentwickler oder -designer können wir nicht alles wissen und sind auch nicht in allen Bereichen gleich kompetent. As beruhigende Gewissheit zitiert Müller deshalb schon im Vorwort Jeffrey Way: »You'll never graduate«. Auch Flexible Boxes verhilft nicht zu einem Doktortitel im Webdesign, das Grundstudium ist damit aber vollständig abgedeckt.
Nils Pooker
»Deutsch für junge Profis: Wie man gut und lebendig schreibt« Wolf Schneider, 2010
Wenn ihr schon etwas mit Klebeband an eurem Monitor befestigt, um es nicht zu vergessen, dann sollte es dieses Buch sein!
Wolf Schneider – Ausbilder an mehreren Journalistenschulen und u.a. Träger des »Medienpreises für Sprachkultur« – führt euch über 32 kleine Rezepte zu klarem, verständlichem Deutsch. Aber Moment, warum sollte ein Webworker ein Buch über deutsche Sprache lesen? Für den Inhalt ist doch schließlich der Kunde zuständig? Ganz klar: Wer als Webworker darauf Wert legt, aus einzelnen Disziplinen wie Usability, Barrierefreiheit, Security, Performance oder Design das Beste herauszuholen, sollte auch vom Content das Beste fordern!
Die kleinen Rezepte drehen sich um den richtigen Einstieg in Texte, Verben, Adjektive, Phrasen, Nebensätze, Redundanzen, Synonyme und einiges mehr – zum Ende geht es auch kurz um Mails, Blogs und Twitter. Ich habe mich beim Lesen ein paar mal über die tollen Beispiele gefreut. Sogar gelacht. Die kurzweilige Schreibweise lädt dazu ein, die 180 Seiten in jedem Jahr einmal neu zu lesen.
Selbst für Webworker, die nie Fachartikel schreiben und auch kein eigenes Blog betreiben, lohnt sich die Lektüre. Schließlich schreiben wir alle Mails, Hilfetexte und Fehlermeldungen fürs CMS, Anleitungen und Dokumentationen. Und auch für die gilt der Leitsatz des Buches: Wer schreibt, möchte auch verstanden werden.
Nicolai Schwarz
»Social Media Marketing & Recht« Thomas Schwenke, O'REILLY (2012)
Ein tolles Grundlagen- und Nachschlagewerk ist für mich das Buch von Rechtsanwalt Thomas Schwenke. Es ist für uns Praktiker geschrieben, die wir für uns oder andere Social-Media-Marketing betreiben. Darin enthalten sind z.B. folgende Themen:
Welche rechtlichen Anforderungen gibt es beim Social Media-Marketing?
Was ist bei der Einrichtung von Social Media-Präsenzen zu beachten?
Alles was man über das Urheberrecht bei der Verwendung von Bildern, Videos und Texten inklusive der Lizenzen von Stockarchive und Creative Commons wissen muss, damit eine Abmahnung vermieden wird.
Rechtliche Stolperfallen bei Gewinnspielen und Direktmarketing und vieles mehr.
Das Buch ist durch die anschaulichen und bebilderten Beispielen sehr gut zu lesen und vermittelt das notwendige Wissen im Umgang mit Social Media und Recht.
Marita Betz
Disclaimer: Die folgenden Bücher können wir ebenso empfehlen. In dieser Liste fallen sie lediglich insofern etwas heraus, als dass sie von Webkrauts stammen.
»Der erfolgreiche Webdesigner« Nils Pooker, Galileo Press (2011)
Eines der wenigen Bücher, das sich eben nicht primär den technischen Aspekten des Jobs, sondern vor allem dem »Drumherum« widmet. In meinen Augen – trotz des Untertitels »Der Praxisleitfaden für Selbstständige« – mindestens aufgrund des ausgiebigen Teils über Kundenkommunikation auch für angestellt arbeitende Webentwickler absolut lesenswert. Und so ganz nebenbei eines der wenigen Fachbücher, die überaus unterhaltsam zu lesen sind.
Matthias Mees
Responsive Webdesign Christoph Zillgens
Es gibt mittlerweile mehrere Bücher zu Responsive Webdesign. Christophs Buch ist aber sowohl faktenreich, als auch sehr schön gestaltet. Es kommt zudem mit einer kostenlosen PDF-Version zum gedruckten Buch daher. Dadurch ist es vielseitig einsetzbar.
Über Responsive Webdesign sollte sich jeder Webworker Gedanken machen und sich informieren. Aus diesem Buch können sowohl Entwickler, als auch Designer und Projektmanager ihren Nutzen ziehen. Die Inhalte werden nicht oberflächlich, aber knapp behandelt. Denn vor allem die richtige Grundhaltung ist für diesen Ansatz wichtig. Und man muss inhaltlich über Online-Quellen am Ball bleiben. Dieses Buch bietet eine prima Grundlage dafür.
Jens Grochtdreis
Nach all den Empfehlungen hat nun der ein oder andere von euch vermutlich seinen eigenen Vorschlag, was als Pflichtlektüre gelten sollte?
Der Web Montag wurde 2005 in Köln aus der Taufe gehoben und bietet
seither eine Plattform für alle Webentwickler, Webdesigner und
Webarchitekten, die kreativ am Fortschritt des Internets teilhaben
wollen und sich mit anderen Enthusiasten auf diesem Gebiet austauschen
möchten. Usprünglich inspiriert vom Hot Spot Silicon Valley ist der
Web Montag heute eine Institution in über 40 Städten mit aktiven
Gruppen in Deutschland, Österreich, Schweden und Kalifornien.
Der zweite Web Montag Kassel findet am 20. Januar statt! Ab 19:00 Uhr
in der Kombinatsgasstätte »Zur Marbachshöhe«, Amalie-Wündisch-Str. 3,
34131 Kassel. Um Voranmeldung via Web Montag Wiki
wird gebeten (das erleichtert uns die Planung).
Übrigens: Wir suchen noch Leute, die den Web Montag Kassel mit guten
Ideen und mit Freude an der Sache unterstützen wollen (Präsentationen,
Organisation, Programmierung etc.). Und natürlich sind wir auch einem
Sponsoring gegenüber nicht abgeneigt (immerhin müssen Örtlichkeiten &
Verköstigung usw. finanziert werden).
Als Webworker können wir Monat für Monat aus einer ganzen Reihe an Konferenzen, BarCamps, Webmontagen und Stammtischen auswählen. Irgendetwas ist immer los. Bei all den vielen Terminen gibt es einige, auf die wir uns besonders freuen. Eine kleine Auswahl.
Vom 17.-21. Februar 2014 findet die Social Media Week unter anderem in Hamburg statt. Das Motto »THE FUTURE OF NOW« bietet viel Fläche für spannende Diskussionen, visionäre Keynotes und interessante Workshops. Und natürlich bietet sich eine gute Gelegenheit, Freunde und Kollegen zu treffen und sein persönliches Social Network zu erweitern.
Bernhard Welzel
Im letzten Jahr hatte ich leider keine Zeit. Dieses Mal will ich auf jeden Fall hin: Zum CMS Garden auf die CeBIT vom 10. bis zum 14. März 2014. Weil sich dort viele große Open-Source-CMS nebeneinander tummeln und es eine großartige Gelegenheit ist, nicht nur Werbung für sein bevorzugtes CMS zu machen, sondern sich auch einmal anzusehen, was all die anderen mittlerweile zu bieten haben.
Nicolai Schwarz
Nach mehrjähriger Pause wird am 20. und 21. März 2014 wieder der Webkongress Erlangen stattfinden. Uns erwarten zwei spannende Tage mit 24 Sessions und ad hoc Vorträgen im Barcamp-Stil rund um Barrierefreiheit, Content Management Systeme und Webdesign. Eine gute Gelegenheit, alte Kontakte aufzufrischen, interessante neue Menschen kennenzulernen und sich auszutauschen.
Kerstin Probiesch
Vom 19.-21. Mai 2014 findet zum vierten Mal die »beyond tellerrand« in Düsseldorf statt, oder wie viele schon sagen »Das Klassentreffen«. Es tut mir leid, liebe Kunden, in diesen Tagen kann Ihre Website leider nicht bearbeitet werden. Denn hier treffen sich alte und neue Bekannte aus dem Web-Volk gleichermaßen, um sich für die tägliche Arbeit inspirieren zu lassen, den Blick vom Projektalltag »über den Tellerrand« zu heben und neues Gedankenfutter zu bekommen.
Dies gelingt nicht nur dank der hervorragenden abwechslungsreichen Talks und der entspannten Atmosphäre im Capitol Theater, in der man sich mit Sprechern und anderen Besuchern austauscht, sondern nicht zuletzt durch das tolle Line-Up, das Organisator Marc Thiele jedes Jahr wieder aus dem Hut zaubert: Dieses mal unter anderem Chris Coyier, Jessica Hische, Jonathan Snook und Erik Spiekermann. Ich bin schon sehr gespannt, wir sehen uns auf jeden Fall!
Frederic Hemberger
Vermutlich im August wird die Konferenz zu Open Source FrOSCon in Bonn stattfinden. Die Themen sind tendenziell eher etwas für Entwickler und Administratoren, steht doch Entwicklung, Betriebssysteme und Sicherheit im Vordergrund. Besonders bemerkenswert ist die offene, freundliche und persönliche Atmosphäre - die »Community« zum Erleben, Anfassen, Eintauchen und Mitmachen!
Bernhard Welzel
Die Konferenz Mensch & Computer ist die jährlich stattfindende Tagung des Fachbereichs Mensch-Computer-Interaktion der Gesellschaft für Informatik e.V. und der German UPA und die führende Veranstaltung zum Thema Mensch-Computer-Interaktion im deutschsprachigen Raum. Nächstes Jahr wird die Tagung mit dem Schwerpunkt »neue Interaktionsformen zwischen Mensch und Systemen« vom 31. August bis zum 3. September an der Ludwig-Maximilians-Universität in München ausgerichtet – für Usability Engineers ein Pflichttermin. Für Besucher, die primär an der praktischen Anwendung interessiert sind, wird die Teiltagung Usability Professionals die interessantesten Sessions bieten. So war das auch im letzten Jahr (Rückblick bei der German UPA, Tagungsband).
Vom 15. – 16. Mai 2014 findet die Contao-Konferenz im Club Office Berlin in Berlin statt.
Die Contao-Konferenz ist die offizielle Konferenz zum gleichnamigen Open Source Content Management System. Was 2008 als familiäres Usertreffen ins Leben gerufen wurde, hat sich mittlerweile zu einer unverzichtbaren Veranstaltung für Interessierte und Profis, welche mit Contao arbeiten, entwickelt. Anders als in den Vorjahren ist der Termin bewusst nicht während eines Feier- oder Brückentages angesetzt.
Organisiert wird die Konferenz seit dem letztem Jahr von der Contao-Association, dem offiziellem Förderverein von Contao. Weitere Informationen zur Themeneinreichung für Sprecher, zum Programmablauf und dem Ticketverkauf folgen in den nächsten Wochen.
Vom 21. bis 23. März 2014 findet in Karlsruhe zum zweiten Mal das DevCamp statt. Diese kleinere Schwesterveranstaltung des etablierten BarCamp Karlsruhe fokussierte sich auf eine ganz spezielle Zielgruppe: Entwickler!
 Gerätesensoren per Javascript und CSS nutzen
Gerätesensoren per Javascript und CSS nutzen
 CSS-Präprozessoren
CSS-Präprozessoren HTML5
HTML5







 SASS für ältere IE nutzen
SASS für ältere IE nutzen, 1798") Kolumne
Kolumne Usability Engineering: Arbeiten mit Nutzungsanforderungen
Usability Engineering: Arbeiten mit Nutzungsanforderungen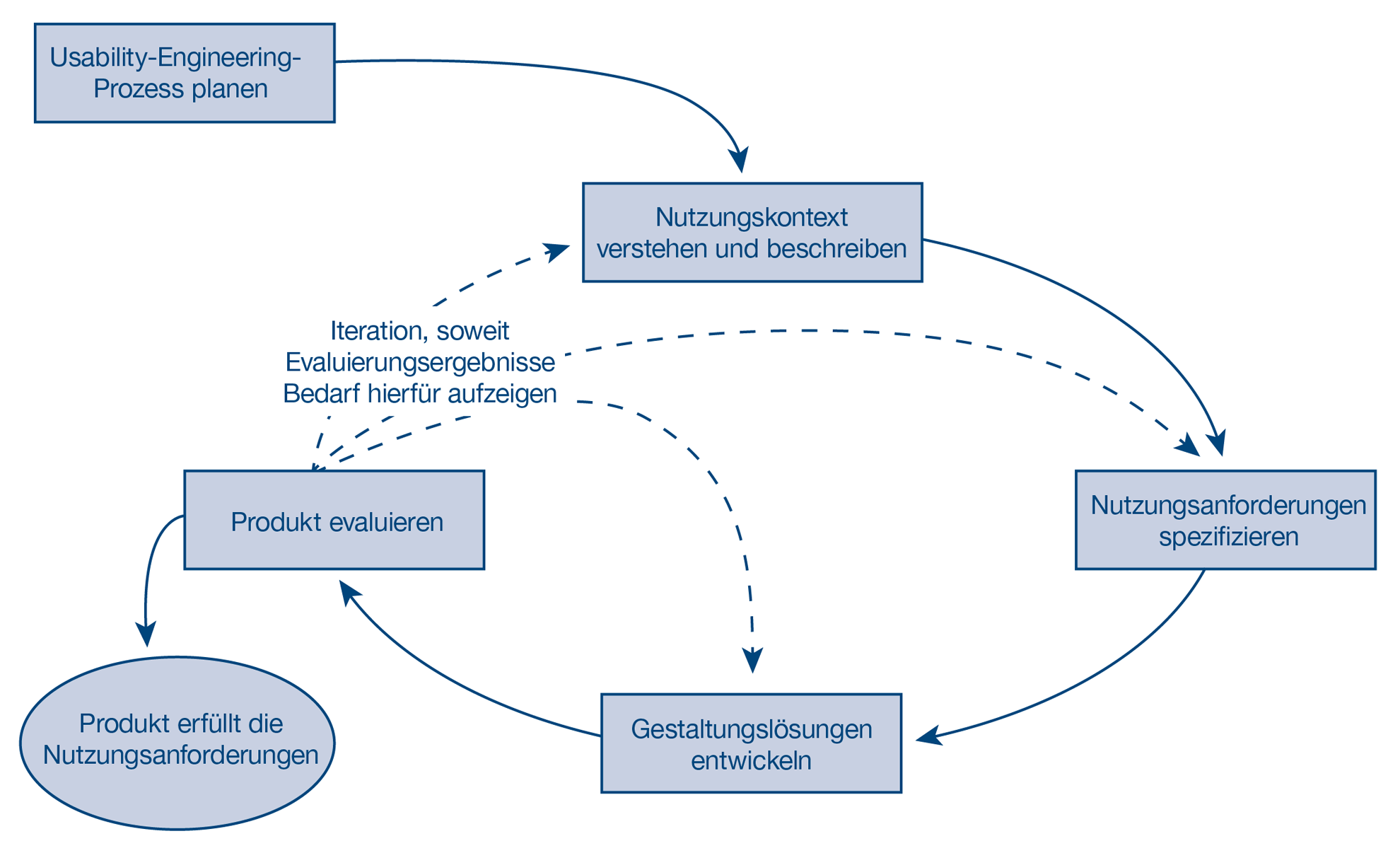


 Usability Engineering: Benutzerzentrierte Analysen in der Praxis
Usability Engineering: Benutzerzentrierte Analysen in der Praxis
 Syntax-Highlighter
Syntax-Highlighter






 Pointer-Events für Maus, Stylus und Touchscreen
Pointer-Events für Maus, Stylus und Touchscreen



 Was heutzutage alles in den Head muss – und was nicht
Was heutzutage alles in den Head muss – und was nicht Was heutzutage alles in den head muss – Teil II
Was heutzutage alles in den head muss – Teil II Animationen mit CSS und JavaScript
Animationen mit CSS und JavaScript Einstieg in Scrum und Kanban – Teil 1
Einstieg in Scrum und Kanban – Teil 1

 Einstieg in Scrum und Kanban – Teil 2
Einstieg in Scrum und Kanban – Teil 2 Buchtipps
Buchtipps Konferenzen und BarCamps
Konferenzen und BarCamps